
本篇文章介绍了如何安装scikit-learn, 并且如何用支持向量机(SVM)识别手写字. 作为一篇scikit-learn入门文章, 并没有深入讲解什么是支持向量机(SVM), 我们的目的仅仅是感受一下什么是机器学习.
下载所需文件
windows环境
- python下载链接:http://pan.baidu.com/s/1i51R98h 密码:xzvi
- wheels下载链接:https://pan.baidu.com/s/1dETxbwd 密码:5jwl
说明:wheel是编译后的python库,为了避免你自己编译(编译时间太长还容易出错)
安装过程
- 安装python
和安装qq一样简单.
- 测试是否安装成功
按下快捷键win+R,打开运行窗口,输入cmd,按下回车,打开命令窗口。
输入python,查看输出结果:
这是正确的输出:
1 | E:\programs\myblog\source\_posts>python |
这是python没有安装成功的输出:
1 | E:\programs\myblog\source\_posts>python |
- 可能出现的问题
1,可能是环境变量没有配置
- 找到python安装在哪里:搜索python,然后右键点击,选择"打开文件所在的位置"
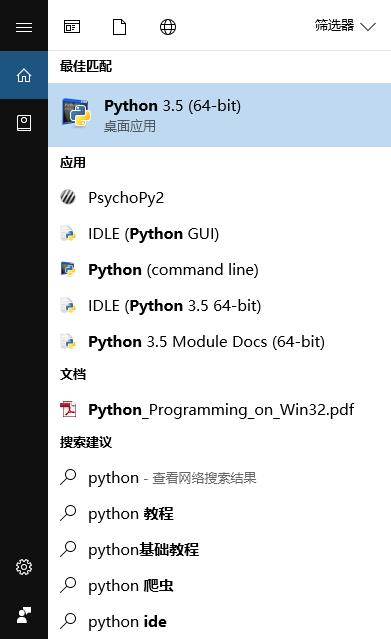
- 复制路径
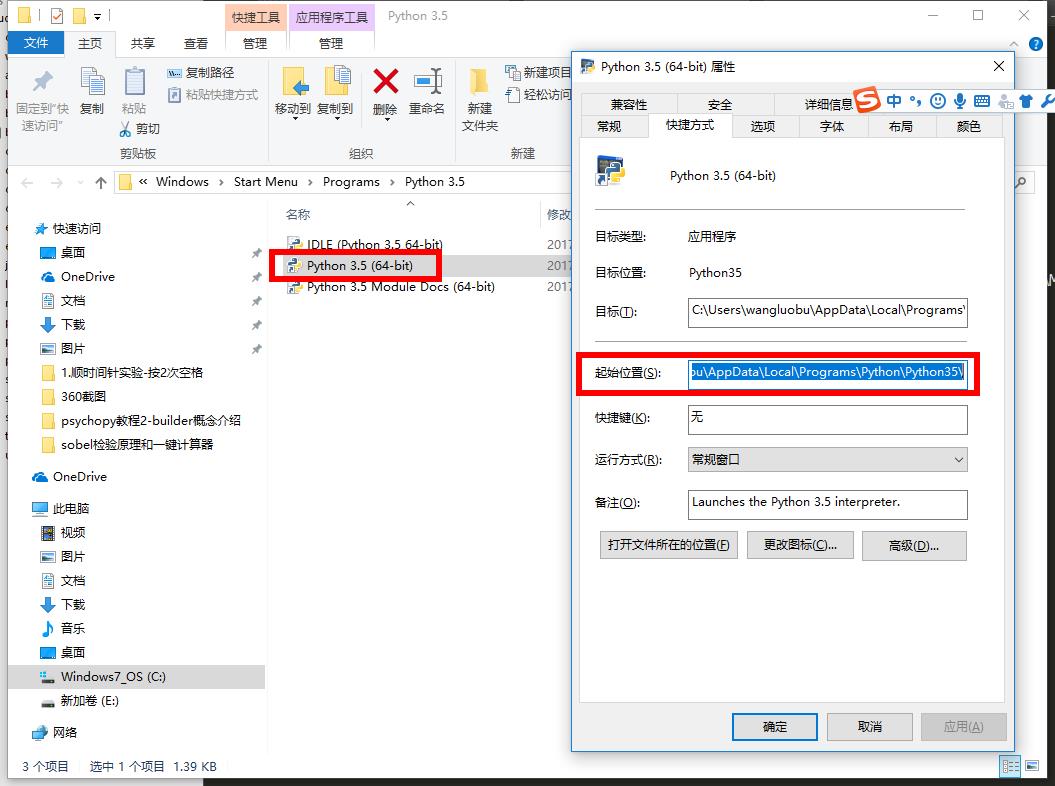
- 编辑路径
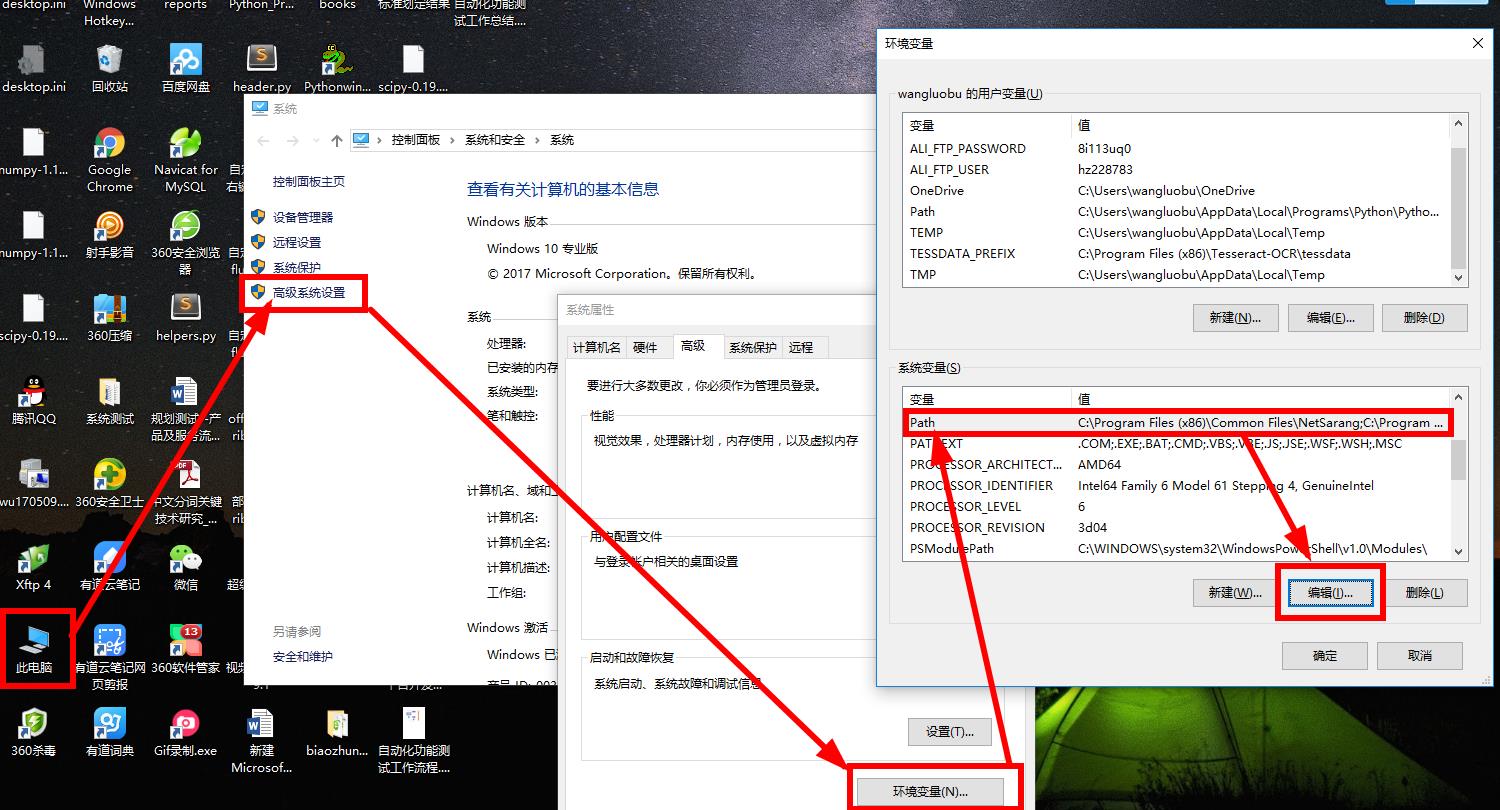
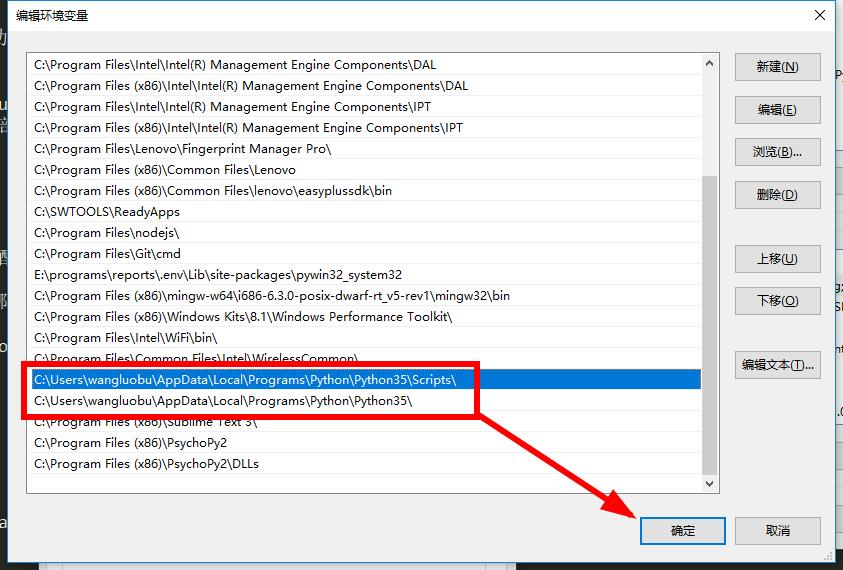
- 添加两个路径,两个路径分别是:
1 | C:\Users\wangluobu\AppData\Local\Programs\Python\Python35 |
两个路径一个是python.exe的目录, 一个是scripts文件夹,这个文件夹里包含很多有用的命令
注意: 你的电脑肯定不是这个路径,每个人的安装路径都可能不同
安装依赖库
- 下载适合的版本
scikit-learn需要两个依赖库:numpy 和 scipy. 建议安装matplotlib用于数据可视化. 从上面的下载链接里下载. 注意自己的电脑是64bit还是32bit, 还需要知道自己的python版本号. 根据这些信息,下载不同的文件.
文件名中包含了python版本和系统位数:
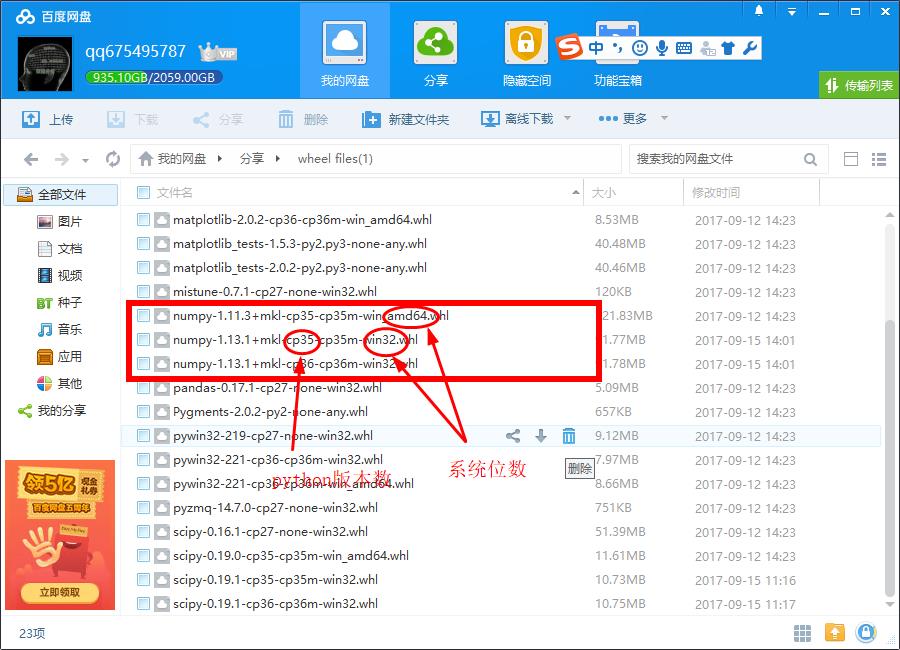
- pip安装
确保你已经联网, 因为安装过程需要下载一些依赖库. 打开cmd, cd到你下载的wheel文件所在文件夹, 然后分步执行以下4条命令:
1 | pip install numpy-1.11.3+mkl-cp35-cp35m-win_amd64.whl |
- 测试是否安装成功
执行如下命令:
1 | import matplotlib |
如果没有报错, 就是安装成功了.
scikit-learn实现手写字识别
- 什么是手写数字
我们不妨看一下scikit-learn内置的手写数字数据集:
1 | from sklearn import datasets |
现在问题是, 怎么以图片方式显示数据?
1 | from matplotlib import pyplot as plt |
- 如何预测手写数字
使用支持向量机模型进行建模, 关于什么是支持向量机, 这里有一个通俗的解释.
1 | from sklearn import svm |
clf就是我们建立的一个svm模型, 我们想要模型具有预测性, 必须进行训练, 训练调用的是clf的fit方法:
1 | clf.fit(digits.data[:-10], digits.target[:-10]) |
预测剩下的10个手写数字:
1 | clf.predict(digits.data[-10:]) |
再看一眼target中存放的正确答案:
1 | digits.target[-10:] |
- 能不能用回归模型?
用最简单的线性回归试试:
1 | from sklearn import linear_model |
为什么输出结果是浮点数? 因为线性回归要求预测值Y必须是连续数据? 我们可以尝试用逻辑回归解决分类问题.
1 | lg=linear_model.LogisticRegression() |
scikit-learn其他案例
神经网络入门
人工神经网络入门-代码实现ORC
讨论
尝试用keras构建一个神经网络识别手写数字. 参考 神经网络python库keras在windows下部署过程,带下载链接