
本篇文章主要用于向非技术人员介绍如何使用python-selenium来简单的采集网页数据的方法。本篇文章用的python版本是3.5 64位,安装32位还是64位python主要看你的系统,如果你的系统是64位,你安装两种版本都可以,但是如果你的系统是32位,你只能选择32的python,chrome-webdriver的下载链接会附的后面。
安装环境
安装python
非常简单,就是一路下一步即可。重点是你要记录下python安装在哪里,一会要用到。
安装selenium
打开Windows的dos窗口,输入如下命令,然后回车
pip install -U selenium
安装浏览器驱动器
首先,你自己要去安装最新的chrome浏览器,这个不在这里介绍。
第二步,从这里下载chrome浏览器的驱动器,链接:http://pan.baidu.com/s/1pKUyrAr 密码:390v
或者你可以从chromedriver的官方网站下载所有版本的chromedriver,包括mac和linux版。地址:https://sites.google.com/a/chromium.org/chromedriver/downloads
chromedriver的版本和chrome的版本必须匹配,比如chrome版本在59-61之间,可以使用chromedriver-2.32,截止发稿日,这是最新的版本。
你会得到一个chromedriver.exe文件,不需要安装,但是你得把它放到python能找到它的地方,你可以通过下图的方式找到python安装在哪里,如图所示,C:\Users\wangluobu\AppData\Local\Programs\Python\Python35\Scripts\就是我要找的位置,我就把chromedriver.exe放到这个目录下。

第三步, 测试是否能从python启动chrome浏览器。
新建一个python程序文件,任何一个以.py结尾的文本文件都可以,你可以把一个记事本文件的后缀名改为py,创建好该文件后,右键单击该文件,选择Edit With IDLE,输入如下代码:
1 | import selenium |
代码填好了,按下快捷键F5就应该能看到chrome浏览器打开,并定位到网站mlln.cn。
chrome网页调试工具
网页开发人员经常会用调试工具来查看网页的源码。chrome浏览器自带调试工具,用chrome打开网址mlln.cn,然后按下F2可以看到调试工具。
你要会定位一个网页元素,进而查看它的源码。使用这个位于左上角的小工具,点击它。
然后点击网页上的标题,你会再代码窗口看到网页标题对应的代码。
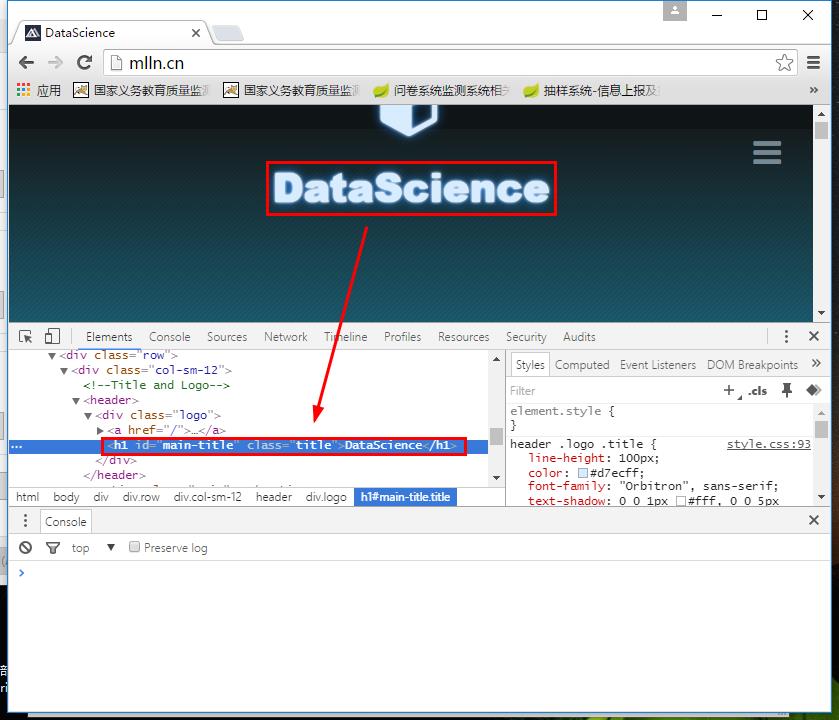
假如现在我们想要采集的数据就是该网页的标题,我们需要写一个python脚本:
1 | import selenium |
你现在知道了,只有配合网页调试工具,我们才能知道我们要的数据在哪里。
selenium 入门
使用selenium需要有网页制作的基础知识,也就是要懂HTML,遇到复杂的问题可以根据HTML知识来解决,如果你不懂HTML,你可以花两天时间了解一下。
定位标签
要知道网页代码是由很多嵌套的标签构成的,为了获取网页中的数据,我们其实就是要获取标签内的文本。
selenium提供了多种方法帮你找到你要的标签。这个列表就是所有:
定位单个标签的方法,他们都返回一个标签。
1 | find_element_by_id #我们刚才用的就是这个方法 |
定位多个标签的方法,这些方法都返回一个列表:
1 | find_elements_by_name |
常用方法举例
find_element_by_id
id是唯一标记html元素的属性,一个页面上不会有重复的id标签,所以你可以使用find_element_by_id快速的找到一个标签。但是有id属性的标签非常少。
加入我们想要获取网站的名字是什么,你需要分析页面上标题的标签,我们还以mlln.cn为例子,它的网站标题标签的代码是<h1 id="main-title" class="title">DataScience</h1>,我们想得到的是标题DataScience:
1 | from selenium import webdriver #引入webdriver |
find_element_by_class_name & find_elements_by_class_name
class是标签的类别,所以通常有多个标签有相同的class,但是如果我们只想得到第一个特定class的标签,那么我们只需要使用find_element_by_class_name,如果我们想要获取所有特定class的标签,我们需要使用find_elements_by_class_name。
比如我们想要获取第一篇文章的发布日期,日期的标签是这样的形式:<span class="date">2017年06月08日</span>,我们看到这个标签的class是date,那么:
1 | first_element=driver.find_element_by_class_name('date') |
或者,我们想要获取所有日期,我们就要用第二个方法:
1 | all_elements=driver.find_elements_by_class_name('date') |
find_element_by_tag_name & find_elements_by_tag_name
tag就是标签的意思,也就是我们本篇文章一直说的html标签,如果我们知道想要某个标签的名字, 比如还是想得到网站标题,它的源码是
1 | <h1 id="main-title" class="title">DataScience</h1> |
1 | first_element=driver.find_element_by_tag_name('h1') |
我们可以看下所有的h1标签都是什么:
1 | for ele in driver.find_elements_by_tag_name('h1'): |
link_text (链接文字)
1 | find_element_by_link_text |
link(链接)大家都知道,点击链接就能跳转到新的页面。我们可以根据链接内的文字获取链接标签。partial_link就是链接的一部分,也就是说你不用输入链接的所有文字,只需要输入一部分,但是这部分文字必须特征明显,以至于能找到你真正想要的链接。
1 | eles=driver.find_elements_by_partial_link_text('数据') |
xpath
xpath是描述html标签位置的方法,需要一些学习成本(大概2小时),通常我们不会用到这种方法,因为比较麻烦。这里已经超出本篇文章的范围,有兴趣的可以在这里学习。
数据存储
通常数据量不太大的时候,我们使用txt文本存储数据就可以了,这种数据用excel也能打开,然后你再进行一些数据转换。
比如现在我们采集了n个用户的m个特征,我们的数据应该是使用嵌套列表来存放数据:
1 | data=[ |
这样的数据是如何形成的?我们模拟一个生成这样的数据的过程:
1 | data=[] #一个空列表用于存放所有用户数据 |
这样的数据我们得写入到一个txt文件中。
1 | file_name='data.txt' |
附录
- 下载chrome浏览器的驱动器,链接:http://pan.baidu.com/s/1pKUyrAr 密码:390v