SPSS 与 Python:循环生成散点图
作者:Ruben Geert van den Berg,归类于 SPSS Python 基础
**** 在 SPSS 中循环处理表格、图表和其他过程的正确方法是使用 Python。我们将通过一些实际例子展示如何操作。我们将使用 alcotest.sav 数据集,部分数据如下所示。请注意,您需要正确安装 SPSS Python Essentials 才能在自己的计算机上运行这些示例。****
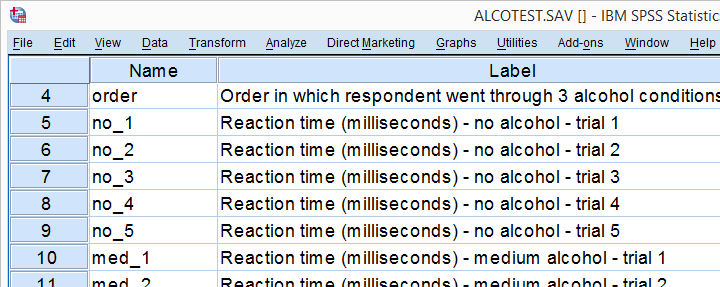
示例 1:简单循环生成条形图
我们想可视化平均反应时间与人们经历 3 种酒精状态顺序之间的关系。我们将首先从菜单生成第一个图表的语法,如下所示。
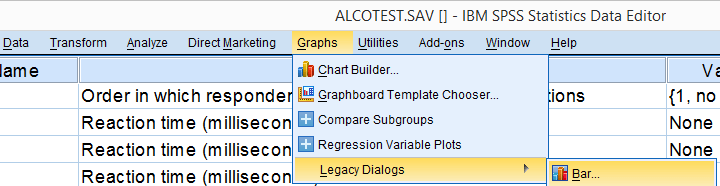
一般来说,尽量使用 L egacy Dialogs (旧版对话框)生成图表。界面和生成的语法非常简单,而且通常可以生成与更复杂的 C hart Builder (图表构建器)完全相同的图表。
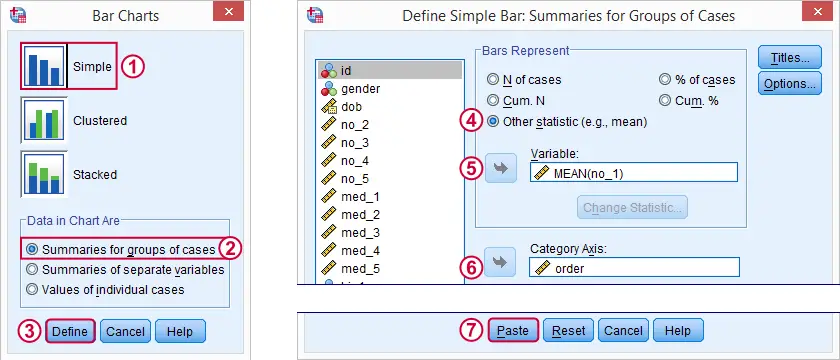
我们将删除粘贴的语法中的所有换行符,得到 GRAPH /BAR(SIMPLE)=MEAN(no_1) BY order.。运行这行代码会生成第一个所需的条形图。为了对不同的反应时间运行类似的图表,我们_可以_复制粘贴该行并将 no_1 替换为 no_2 等等。然而,更简洁的方法是使用下面的 Python 语法。
SPSS Python 循环语法 1
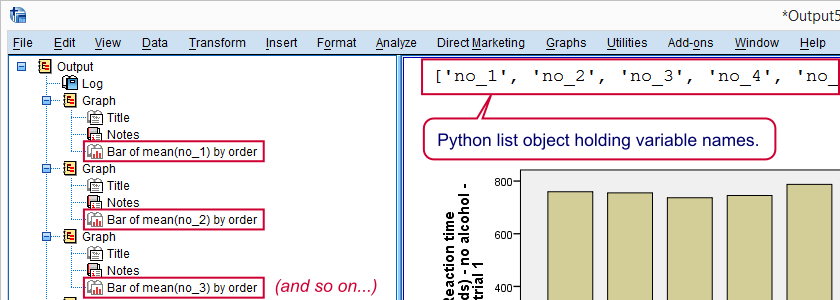
手动将变量名指定为 Python 列表对象并打印出来。
begin program.
import spss
varList = ['no_1','no_2','no_3','no_4','no_5']
print varList
end program.如果变量列表没问题,则循环处理它。
begin program.
for var in varList:
spss.Submit('''
GRAPH /BAR(SIMPLE)=MEAN(%s) BY order.
'''%(var))
end program.注意
您可能会注意到第二个代码块末尾附近的条形图语法。唯一的区别是变量名已被替换为 %s。这是一个 Python 字符串占位符,它将在每次迭代中被替换为不同的变量名。
结果
示例 2:从数据中查找变量名
我们不喜欢第一个示例的一点是需要拼写出变量名。Python 可以通过多种方式从您的数据中检索它们。一个 始终有效的方法 是使用 SPSS 的 TO 和 ALL 关键词指定变量名。如下所示,该规范可以扩展为 Python 列表,您可以根据需要循环处理它。
从数据中检索变量名并打印出来以供检查。
begin program.
import spss,spssaux
varSpec = "no_1 to hi_5" # 使用 SPSS TO 或 ALL 关键词指定变量
varDict = spssaux.VariableDict(caseless = True)
varList = varDict.expand(varSpec)
varList.sort(key = lambda x: varDict.VariableIndex(x))
print varList
end program.如果变量列表没问题,则循环处理它。
begin program.
for var in varList:
spss.Submit('''
GRAPH /BAR(SIMPLE)=MEAN(%s) BY order.
'''%(var))
end program.示例 3:并行循环
现在,我们想检查在 5 次试验中,无酒精与中等酒精的反应时间的散点图。与之前一样,我们将首先生成一个散点图的语法,如下所示。
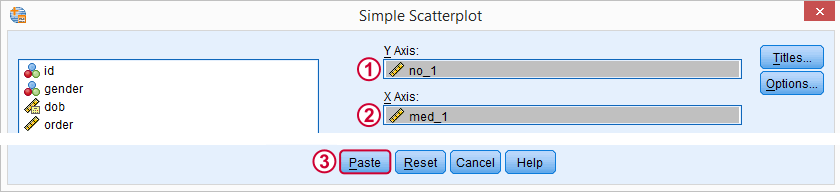
删除所有换行符后,这些步骤将生成 GRAPH /SCATTERPLOT(BIVAR)=med_1 WITH no_1 /MISSING=LISTWISE.。
按模式检索变量名
下面的语法设置两个空的 Python 列表,并循环处理我们数据中的所有变量名。以 “no_” 开头的变量名被添加到第一个列表中,而以 “med_” 开头的变量名被添加到另一个列表中。最后,我们将并行循环处理这两个列表以生成散点图。
按名称中的模式检索变量名并打印出来。
begin program.
import spss
noVars,medVars = [],[] # 设置两个空列表
for varInd in range(spss.GetVariableCount()): # 循环处理所有变量索引
varName = spss.GetVariableName(varInd)
if varName.startswith('no_'): # 如果变量名中存在模式...
noVars.append(varName) # ...添加到列表
elif varName.startswith('med_'):
medVars.append(varName)
print noVars,medVars
end program.如果变量列表没问题,则对它们运行并行循环。
begin program.
for listInd in range(len(noVars)):
spss.Submit('''
GRAPH /SCATTERPLOT(BIVAR)= %s WITH %s /MISSING=LISTWISE.
'''%(noVars[listInd],medVars[listInd]))
end program.注意
第二个代码块循环处理列表索引(“listInd”),这些索引指的是_任一_列表中的第一个、第二个、…元素。然后,Python 使用 noVars[listInd] 从任一列表中检索第一个、第二个、…变量名。
示例 4:使用连接创建变量名
我们现在将展示一个更简单的散点图选项,如果变量名以简单的 数字后缀 结尾,这将有效。我们将简单地循环处理一个包含数字 1 到 5 的列表(由 range(1,6) 生成),并将这些数字连接到变量名根。
通过将变量名根与数字后缀连接来生成变量名。
begin program.
import spss
for varSuffix in range(1,6): # range(1,6) 的值为 [1, 2, 3, 4, 5]
spss.Submit('''
GRAPH /SCATTERPLOT(BIVAR)=no_%(varSuffix)d WITH med_%(varSuffix)d /MISSING=LISTWISE.
'''%locals())
end program.注意
在 Python 中,%d 是一个通用的 整数占位符。它被稍后指定的某个整数替换。
或者,如果最后指定了 %locals(),则 %(varSuffix)d 将被 varSuffix 中的整数替换。 使用 %locals() 可以使您的代码更具可读性和更短,尤其是在有多个(文本或数字)占位符的情况下。
示例 5:下三角循环
我们的最后一个示例创建一组变量之间 所有可能的 不同的散点图。也就是说,如果我们运行这些变量的 相关性 矩阵,则主对角线下方的每个单元格(因此称为“下三角”)都会在散点图中可视化。这次,我们将通过 变量视图 下的索引查找变量名,如下所示。

语法
按索引检索变量名。
begin program.
import spss,spssaux
noVars = spssaux.GetVariableNamesList()[4:9] # SPSS 变量视图中的第 5 到第 9 个变量
print noVars
end program.下三角循环。
begin program.
for i in range(len(noVars)):
for j in range(len(noVars)):
if i < j:
spss.Submit('''
GRAPH /SCATTERPLOT(BIVAR)=%s WITH %s /MISSING=LISTWISE.
'''%(noVars[i],noVars[j]))
end program.最后的说明
解释每一行 Python 代码都超出了本教程的范围。但是,通过一些尝试和错误(以及 Google),您可以改编并在自己的项目中 重用这些示例。或者我们希望如此。试一试。你会成功的。感谢您的阅读。