在 SPSS 中创建 APA 样式的描述性统计表
作者:Ruben Geert van den Berg,发表于 SPSS 中的表格
在 SPSS 中使用 DESCRIPTIVES 命令运行一些基本的描述性统计非常容易。但是,生成的表格甚至无法达到 APA 要求的格式或企业客户通常要求的格式。
问题是什么?如果您尝试创建如下所示的表格,您会很快发现问题所在。
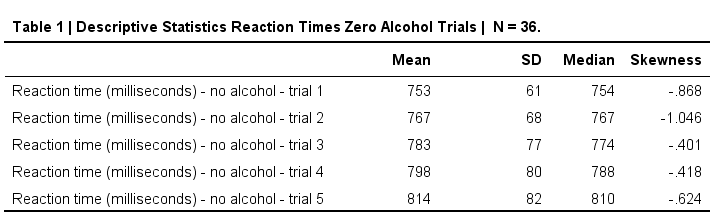 简洁美观的 APA 描述性统计表。
简洁美观的 APA 描述性统计表。
SPSS DESCRIPTIVES 示例
此表基于 alcotest.sav 中的 no_1 到 no_5。当尝试使用 DESCRIPTIVES 创建它时,我能得到的最接近的结果是下面的 语法 (syntax)。
descriptives no_1 to no_5
/statistics means stddev skewness.结果
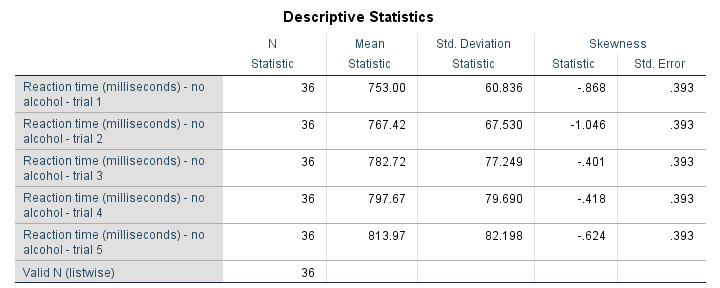
虽然这个表格很容易创建,并且在探索数据时效果很好,但它并不完全符合要求。因此,让我们深入研究一些问题。
DESCRIPTIVES 中没有中位数 (Median)
由于某些奇怪的原因,DESCRIPTIVES 不包括 中位数 (median)。说真的,我在 CSR (Command Syntax Reference) 中查找了它,但就是没有。

DESCRIPTIVES 不包括中位数。好吧,那么我们暂时跳过中位数,进入第二个问题。
不需要的推论统计 (Inferential Statistics)
对于某些统计量(包括 偏度 (skewness) 和 峰度 (kurtosis)),SPSS 会自动报告它们的标准误差 (standard errors)。但是:如果我想要标准误差,我会要求的。

DESCRIPTIVES 表格的屏幕截图,包括一些不需要的标准误差。如果我不要求它们,那么我可能不想要它们。但我还是得到了它们。我对此有几个问题:
- 标准误差会导致表格格式复杂,包含合并的单元格。删除或隐藏这些不需要的单元格很复杂。至少,我没有找到一种快速简便的方法。
- 标准误差不是描述性的,而是 推论统计 (inferential statistics)。只有当我的数据是从总体中抽取的简单随机样本时,它们才是正确的。
- 如果我的数据占总体的很大一部分,这些标准误差是有偏差的(偏离零)。在这种情况下,我需要对标准误差应用所谓的有限校正。需要 SPSS 复杂抽样选项(模块)才能做到这一点。
- 如果我抽取了整个总体,则报告的标准误差是毫无意义的。在这种情况下,没有抽样误差,因此正确的标准误差都为零。
不需要的 N 列
当我在探索我的数据时,我喜欢看到每个变量的 N 值。它告诉我每个变量有多少 缺失值 (missing values)。但是,如果没有缺失值,我就不想要此列。在这种情况下,我宁愿在表格的标题中报告 N 值。但是,使用 DESCRIPTIVES 时无法省略 N 值。
无法省略 “Valid N (listwise)”
类似地,DESCRIPTIVES 始终包含 “Valid N (listwise)”。这告诉我,有多少个案在表格中包含的所有变量上都有零个缺失值。在准备数据时——特别是对于多变量分析——这很好。但是,“Valid N (listwise)” 让我的非 SPSS 用户客户感到困惑,他们不想看到它。幸运的是,SPSS Python 脚本可以很好地隐藏它。尽管如此,能够选择是否包含它,而不是始终包含它然后不得不隐藏它,会更好。
SPSS APA 格式相关性 中也提出了类似的观点。
CELLS 还是 STATISTICS?
运行
CROSSTABS时,CELLS子命令指定我的列联表应包含哪些单元格。 接下来,可以使用STATISTICS指定 统计显著性 (statistical significance) 的检验——通常是 卡方独立性检验 (chi-square independence test)。CROSSTABS中的STATISTICS还会创建几个相关性,例如 Pearson 相关性 (Pearson correlations)、Cramér’s V、Spearman 等级相关性 (Spearman rank correlations) 和许多其他统计量。运行
MEANS时,CELLS子命令指定我的均值表应包含哪些单元格。 接下来,可以使用STATISTICS指定统计显著性的检验——单因素 ANOVA (one-way ANOVA)。运行
DESCRIPTIVES时,没有CELLS子命令。STATISTICS指定我的描述性统计表应包含哪些单元格。
表格样式 (Table Styling)
如果您使用的是 SPSS 22 或更早版本,则您的描述性统计表可能如下所示。不是非常漂亮,但干净而体面。
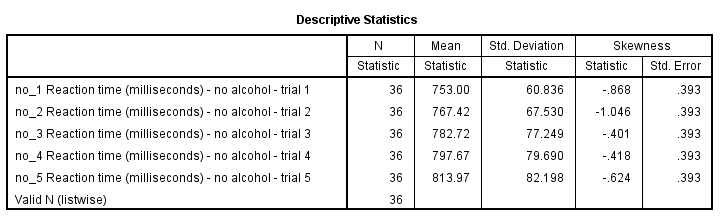
DESCRIPTIVES 表格由于某些原因,SPSS 23 引入了新的表格样式,其中灰色文本显示在灰色背景上。我不喜欢它们在屏幕上的显示方式,更不用说打印出来了。
如果您比新的样式更喜欢旧的样式,则可以通过将 Original.stt 设置为您的 tablelook 来恢复它们。在我的系统中,set tlook "C:\Program Files\IBM\SPSS\Statistics\24\Looks\**Original.stt**". 可以解决问题。
使用 MEANS 获得更好的描述性统计表
那么如何在 APA 格式中创建此描述性统计表?好吧,这非常简单。只需运行
means no_1 to no_5
/cells mean stddev median skew.并转置生成的表格。这给我们留下了一个问题:如何在 SPSS 中转置表格?
在 SPSS 中转置枢轴表 (Pivot Tables)
与图表模板 (chart templates) 相比,表格模板 (table templates) 无法为您转置输出 - 这很不幸,因为它会节省大量时间。因此有 3 个选项:
- 手动:右键单击表格,选择 “_E_dit Content”
 “In Separate _W_indow”,然后重新排列枢轴托盘。有关示例,请参阅 SPSS 卡方独立性检验(向下滚动)。
“In Separate _W_indow”,然后重新排列枢轴托盘。有关示例,请参阅 SPSS 卡方独立性检验(向下滚动)。 - Python:SPSS Python 脚本可以为您转置输出窗口中的一个、多个或所有枢轴表。这需要您正确安装 SPSS Python Essentials。
- 最后但并非最不重要的一点是,如果您使用的是 SPSS 22 或更高版本,OUTPUT MODIFY 可以通过少量语法快速完成这项工作。我将在下面添加一个例子。
***转置所有 MEANS 表格(但不包括案例处理摘要)。
OUTPUT MODIFY
/SELECT TABLES
/IF commands = ["means"] subtypes =["report"]
/TABLE TRANSPOSE=YES.感谢阅读。