使用 Python 处理多个 SPSS 数据文件
作者:Ruben Geert van den Berg,出自 SPSS Python 基础
一次性对多个 SPSS 数据文件运行语法非常简单。如果我们使用 SPSS with Python,我们甚至不必键入文件名。Python 的 os (代表 operating system,操作系统) 模块将为我们完成这项工作。
您可以自行尝试:下载 spssfiles.zip。将这些文件解压缩到 d:\spssfiles 中,如下所示,就可以开始了。
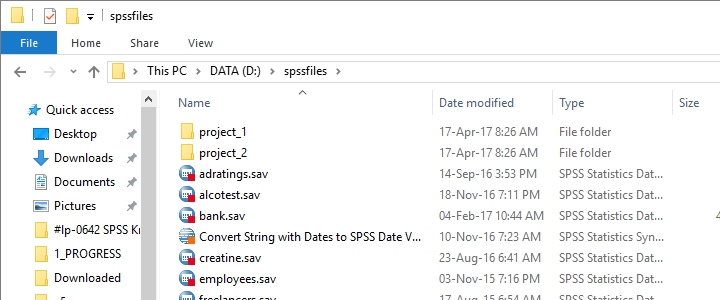
查找根目录中的所有文件和文件夹
以下语法创建一个 Python 列表,其中包含 rDir(即我们的根目录)中的文件和文件夹。在它前面加上 r,如 r'D:\spssfiles',可确保 反斜杠 不会产生任何奇怪的行为。
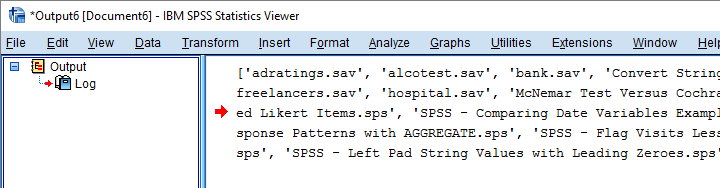
查找根目录中的所有文件和文件夹。
begin program python3.
import os
rDir = r'D:\spssfiles'
print(os.listdir(rDir))
end program.结果
过滤出所有 .Sav 文件
正如我们所看到的,os.listdir() 创建了一个包含 rDir 中所有文件和文件夹的列表,但我们只想要 SPSS 数据文件。为了过滤掉它们,我们首先使用 savs = [] 创建一个空列表。接下来,如果文件以 endswith(".sav") 结尾,我们将把每个文件添加到这个列表中。
将所有 .sav (SPSS 数据) 文件添加到 Python 列表。
begin program python3.
import os
rDir = r'D:\spssfiles'
savs = []
for fil in os.listdir(rDir):
if fil.endswith(".sav"):
savs.append(fil)
print(savs)
end program.使用 SPSS 文件的完整路径
为了对我们的数据文件做任何事情,我们可能需要打开它们。为此,SPSS 需要知道它们位于哪个文件夹中。我们可以简单地使用 CD 在 SPSS 中设置一个默认目录,例如 CD "d:\spssfiles"。然而,让 Python 使用 os.path.join() 创建文件的完整路径是一种更可靠的方法。
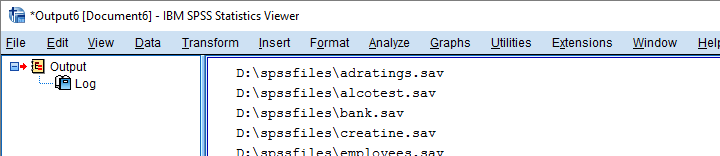
创建所有 .sav 文件的完整路径。
begin program python3.
import os
rDir = r'D:\spssfiles'
savs = []
for fil in os.listdir(rDir):
if fil.endswith(".sav"):
savs.append(os.path.join(rDir,fil))
for sav in savs:
print(sav)
end program.结果
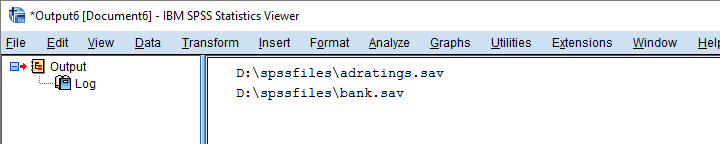
让 SPSS 打开每个数据文件
通常,我们使用类似 GET FILE "d:\spssfiles\mydata.sav" 的命令在 SPSS 中打开一个数据文件。如果我们将文件名替换为 Python 列表中每个路径,我们将逐个打开每个数据文件。然后,我们可以添加一些我们想要在每个文件上运行的语法。最后,我们可以使用 SAVE OUTFILE "..." 保存我们的编辑,这将批量处理多个文件。然而,在这个例子中,我们将简单地使用 spssaux.GetVariableNamesList() 查找每个文件包含哪些变量。
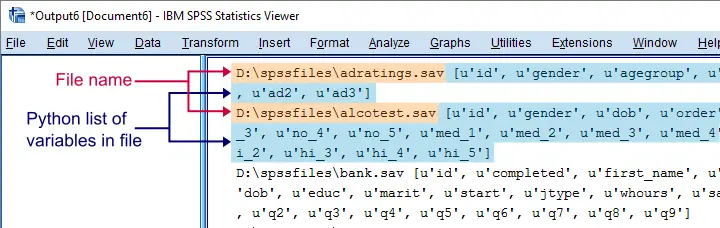
打开所有 SPSS 数据文件并打印它们包含的变量。
begin program python3.
import os,spss,spssaux
rDir = r'D:\spssfiles'
savs = []
for fil in os.listdir(rDir):
if fil.endswith(".sav"):
savs.append(os.path.join(rDir,fil))
for sav in savs:
spss.Submit("GET FILE '%s'."%sav)
print(sav,spssaux.GetVariableNamesList())
end program.结果
检查哪些文件包含 “Salary”
现在假设我们想知道哪些文件包含变量“salary”。我们将简单地检查它是否存在于我们的变量名列表中,如果存在,则返回数据文件的名称。
报告所有包含变量 “salary” (区分大小写) 的 .sav 文件。
begin program python3.
import os,spss,spssaux
rDir = r'D:\spssfiles'
findVar = 'salary'
savs = []
for fil in os.listdir(rDir):
if fil.endswith(".sav"):
savs.append(os.path.join(rDir,fil))
for sav in savs:
spss.Submit("get file '%s'."%sav)
if findVar in spssaux.GetVariableNamesList():
print(sav)
end program.结果
规避 Python 的大小写敏感性
我想介绍的还有一点:由于我们搜索的是“salary”,Python 不会检测到“Salary”或“SALARY”,因为它完全区分大小写。如果你不喜欢这样,简单的解决方案是将所有文件的所有变量名转换为 lower() 小写。
更改 Python 列表中的所有项目 的一种基本方法是 [i... for i in list],其中 i... 是 i 的修改版本,在我们的例子中是 i.lower()。这种技术被称为 Python 列表推导式,下面的语法使用它将所有变量名转换为小写 (第 13 行)。
报告所有包含变量 “salary” (不区分大小写) 的 .sav 文件。
begin program python3.
import os,spss,spssaux
rDir = r'D:\spssfiles'
findVar = 'salary'
savs = []
for fil in os.listdir(rDir):
if fil.endswith(".sav"):
savs.append(os.path.join(rDir,fil))
for sav in savs:
spss.Submit("get file '%s'."%sav)
if findVar.lower() in [varNam.lower() for varNam in spssaux.GetVariableNamesList()]:
print(sav)
end program.注意:由于我通常避免在 SPSS 变量名中使用任何大写字母,因此结果与我们区分大小写的搜索相同。