SPSS AGGREGATE 命令
作者:Ruben Geert van den Berg,归属于SPSS A-Z系列。
Aggregate 是一个 SPSS 命令,用于创建包含_跨案例_统计信息的变量。本教程简要演示了最常见的场景,并指出了一些最佳实践。
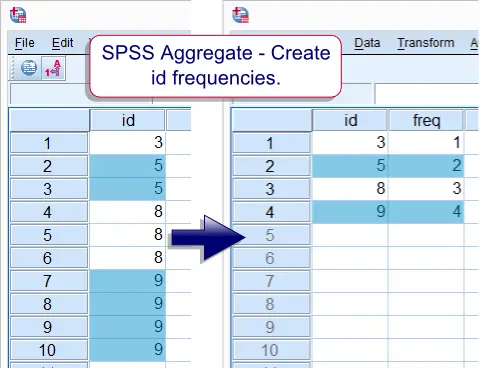
SPSS AGGREGATE 命令
SPSS 的 AGGREGATE 命令通常按如下方式工作:
- 可以指定一个或多个
BREAK变量。在 SPSS 15 及更早版本中,必须指定至少一个BREAK变量。如果需要对所有案例进行统计,请使用compute constant = 0.并使用constant作为 BREAK 变量。 - 在
BREAK变量上具有相同值的所有案例被称为中断组 (break group)。 - 每个中断组将成为聚合数据中的单个案例(除非使用
MODE = ADDVARIABLES)。 - 这个新的案例将原始案例的汇总统计信息作为新的变量。可用的统计信息包括频率 (frequency),均值 (mean),最大值 (maximum) 等等。有关完整概述,请参阅命令语法参考。
AGGREGATE的结果可以是活动数据集 (active dataset)、新的数据集 (new dataset) 或新的数据文件。 (最后一个选项不适用于MODE = ADDVARIABLES。)新的数据集必须先声明,然后才能在AGGREGATE中指定。- 对于一个非常基本的演示,请运行下面的 语法。
SPSS Aggregate 语法示例
***1. 创建测试数据。***
data list free/id.
begin data
3 5 5 8 8 8 9 9 9 9
end data.
***2. 创建包含 id 计数的 Dataset(名为 'freq',代表 'frequency')。***
aggregate outfile *
/break id
/freq = nu.MODE = ADDVARIABLES
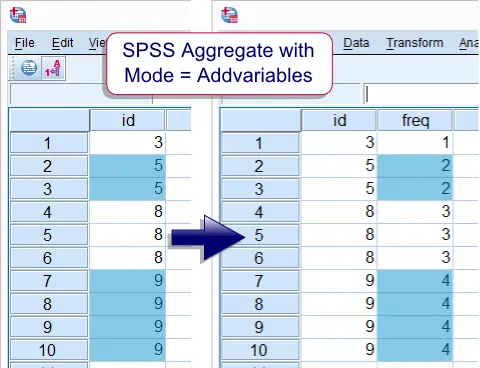 SPSS Aggregate - Mode = Addvariables
SPSS Aggregate - Mode = Addvariables
除了 SPSS 12 及更早版本外,中断组的汇总统计信息可以附加到数据集,而无需实际聚合它。以下语法演示了这一点。
SPSS Aggregate 语法示例
***将 id 计数附加到 Dataset。***
aggregate outfile * mode = addvariables
/break id
/freq = nu.跨多个变量的统计
可以一次性呈现跨多个变量的汇总统计信息。TO 和 ALL 关键字可以方便地缩短变量列表,如下面的语法所示。
***1. 创建测试数据。***
data list free/v1 to v5.
begin data
1 2 3 4 5 6 7 8 9 10
end data.
***2. 一次聚合多个变量。***
aggregate outfile *
/mean_1 to mean_5 = mean(v1 to v5).多个统计信息
可以在单个命令中指定不同的汇总统计信息(针对相同或不同的变量)。 下面演示了这一点(使用上一个示例中的测试数据)。
***单个命令中的不同汇总统计信息。***
aggregate outfile *
/mean_1 to mean_5 = mean(v1 to v5)
/sd_1 to sd_5 = sd(v1 to v5).最终说明
可以使用 AGGREGATE 命令完成许多不同的事情。 本教程旨在说明实践中最常见的场景。 它绝不打算作为所有选项的详尽概述。