在 SPSS 中打开 Excel 文件
作者:Ruben Geert van den Berg,发表于 SPSS 博客
- 在 SPSS 中打开包含值的 Excel 文件
- 应用 Excel 中的变量标签
- 应用 Excel 中的值标签
- 在 SPSS 中打开包含字符串的 Excel 文件
- 转换 Excel 中的字符串变量
包含社会科学数据的 Excel 文件主要分为两种基本类型:
- 包含数据值(1, 2, …)和变量名(v01, v02, …),并在单独的工作表中说明数据代表什么,如 course-evaluation-values.xlsx 所示;
- 包含答案类别(“好”,“坏”,…)和问题描述(“你觉得…怎么样”)的文件,如 course-evaluation-labels.xlsx 所示。
在 SPSS 中简单地打开任何一个文件都很容易。但是,为分析准备数据可能具有挑战性。本教程将快速引导您完成整个过程。
在 SPSS 中打开包含值的 Excel 文件
首先,让我们修复 course-evaluation-values.xlsx 文件,部分内容如下所示。
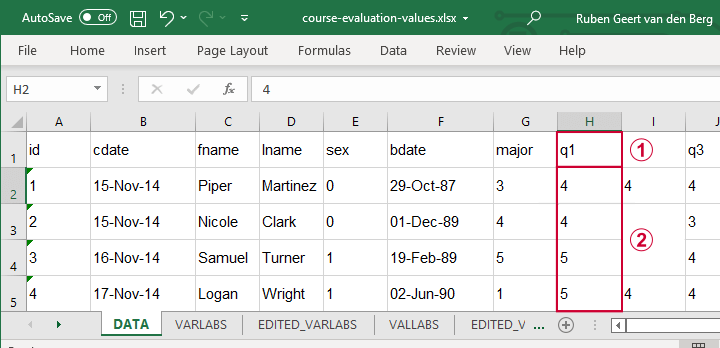
 数据表具有简短的变量名,其描述位于另一个工作表 VARLABS(“变量标签”的缩写)中;
数据表具有简短的变量名,其描述位于另一个工作表 VARLABS(“变量标签”的缩写)中;
 答案类别用数字表示,其描述位于 VALLABS(“值标签”的缩写)中。
答案类别用数字表示,其描述位于 VALLABS(“值标签”的缩写)中。
让我们首先通过导航到“F 文件(File)”  “导入 D 数据(Import Data)” “E xcel(Excel)”来简单地在 SPSS 中打开实际的数据表,如下所示。
“导入 D 数据(Import Data)” “E xcel(Excel)”来简单地在 SPSS 中打开实际的数据表,如下所示。
接下来,填写如下所示的对话框。提示:您也可以通过将 Excel 文件拖放到 SPSS 数据编辑器窗口中来打开这些对话框。
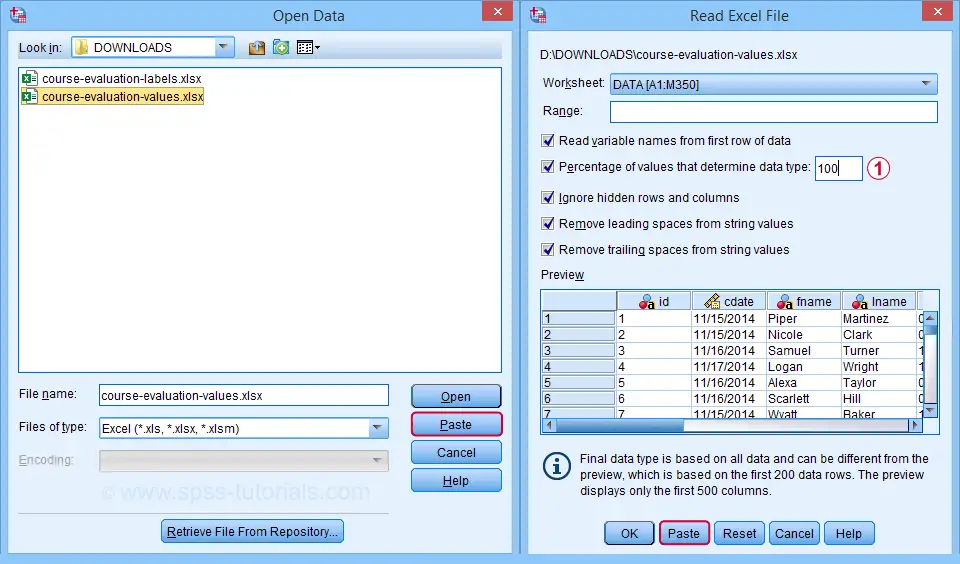
默认情况下,如果 Excel 列的值中至少有 95% 是数字,SPSS 会将其转换为数值变量。其他值会转换为 系统缺失值(system missing values),而不会告诉您哪些或多少个值已消失。这是 非常 危险的,但我们可以通过将其设置为 100 来防止这种情况。
完成这些步骤将生成如下所示的 SPSS 语法(SPSS syntax)。
***IMPORT EXCEL FILE.
**
GET DATA
/TYPE=XLSX
/FILE='D:\data\course-evaluation-values.xlsx'
/SHEET=name 'DATA'
/CELLRANGE=FULL
/READNAMES=ON
/LEADINGSPACES IGNORE=YES
/TRAILINGSPACES IGNORE=YES
/DATATYPEMIN PERCENTAGE=100.0
/HIDDEN IGNORE=YES.结果
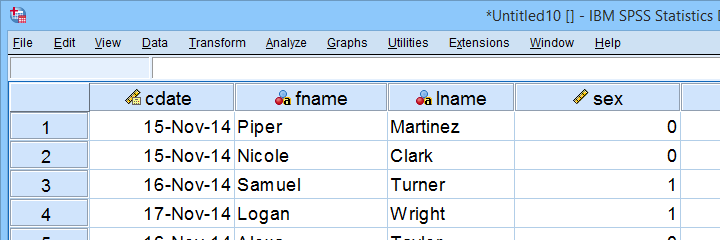
如图所示,我们实际的数据现在位于 SPSS 中。但是,我们仍然需要从其他 Excel 工作表中添加它们的标签。让我们从变量标签开始。
应用 Excel 中的变量标签
设置变量标签的一种快速简便的方法是使用 Excel 公式创建 SPSS 语法:我们基本上在每个标签周围添加单引号,并在其前面加上变量名,如下所示。
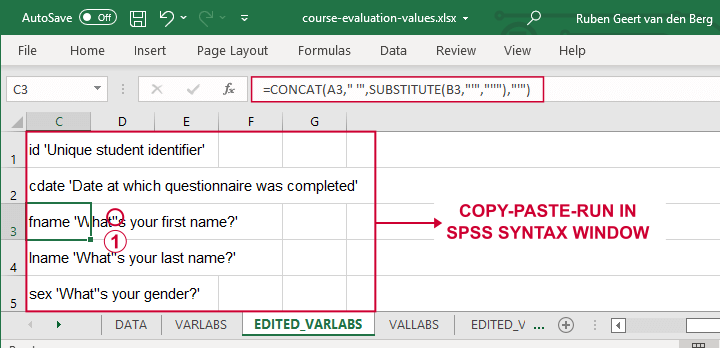
如果我们在标签 周围 使用单引号,我们需要用 2 个单引号替换标签 内部 的单引号。
最后,我们只需将这些单元格复制粘贴到语法窗口中,在其前面加上 VARIABLE LABELS,并在最后一行的末尾加上句点。下面的语法显示了由此创建的前几行。
***VARIABLE LABELS SYNTAX - MOSTLY COPY-PASTED FROM EXCEL FORMULAS.
**
variable labels
id 'Unique student identifier'
cdate 'Date at which questionnaire was completed'.应用 Excel 中的值标签
现在,我们将使用相同的基本技巧设置值标签。这次 Excel 公式有点难,但仍然可以做到。
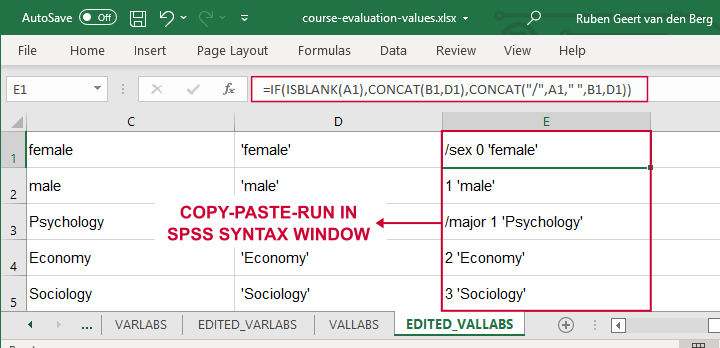
让我们将 E 列复制粘贴到 SPSS 语法窗口中,并向其添加 VALUE LABELS 和句点。下面的语法显示了前几行。
***VALUE LABELS SYNTAX - MOSTLY COPY-PASTED FROM EXCEL FORMULAS.
**
value labels
/sex 0 'female'
1 'male'
/major 1 'Psychology'
2 'Economy'
3 'Sociology'
4 'Anthropology'
5 'Other'.运行这些行后,我们就差不多完成了此文件。快速说明:如果您需要转换 许多 Excel 文件,可以使用简单的 Python 脚本自动执行此过程。
在 SPSS 中打开包含字符串的 Excel 文件
现在让我们转换 course-evaluation-labels.xlsx 文件,部分内容如下所示。
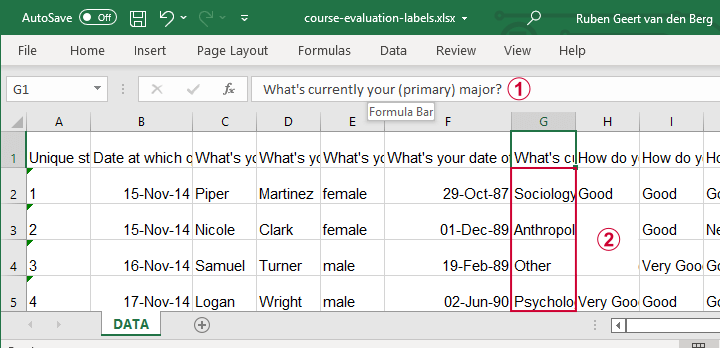
请注意,Excel 列标题是完整的问题描述;
Excel 单元格包含实际的答案类别。
让我们首先在 SPSS 中打开此 Excel 工作表。我们将使用与“在 SPSS 中打开包含值的 Excel 文件”中完全相同的步骤进行操作,从而产生以下语法。
***IMPORT EXCEL FILE.
**
GET DATA
/TYPE=XLSX
/FILE='d:/data/course-evaluation-labels.xlsx'
/SHEET=name 'DATA'
/CELLRANGE=FULL
/READNAMES=ON
/LEADINGSPACES IGNORE=YES
/TRAILINGSPACES IGNORE=YES
/DATATYPEMIN PERCENTAGE=100.0
/HIDDEN IGNORE=YES.结果
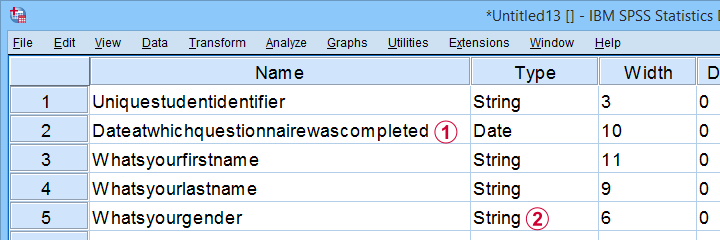
此 Excel 工作表在 SPSS 中产生巨大的变量名;
大多数 Excel 列已成为 SPSS 中的 字符串变量(string variables)。
现在让我们解决这两个问题。
缩短变量名
我强烈建议使用短变量名。您可以使用 RENAME VARIABLES (ALL = V01 TO V13) 来设置这些变量名。在此之前,请确保所有变量都具有合适的变量标签。如果有些变量标签为空,我通常将其变量名设置为标签。这通常是我们从 Excel 列标题中获得的全部信息。
下面显示了一个用于执行此操作的简单 Python 脚本。
***SET VARIABLE NAMES AS VARIABLE LABELS IF THEY ARE EMPTY.
**
begin program python3.
import spss
spssSyn = ''
for i in range(spss.GetVariableCount()):
varlab = spss.GetVariableLabel(i)
if not varlab:
varnam = spss.GetVariableName(i)
if not spssSyn:
spssSyn = 'VARIABLE LABELS'
spssSyn += "\n%(varnam)s '%(varnam)s'"%locals()
if spssSyn:
print(spssSyn)
spss.Submit(spssSyn + '.')
end program.转换 Excel 中的字符串变量
那么如何将我们的字符串变量转换为数值变量呢?这取决于这些变量中的内容:
- 对于包含数字的定量字符串变量,请尝试 ALTER TYPE;
- 对于名义答案类别,请尝试 AUTORECODE;
- 对于有序答案类别,请使用 RECODE 或尝试 AUTORECODE,然后调整其顺序。
例如,以下语法将“id”转换为数值。
***CONVERT V01 TO NUMERIC.
**
alter type v01 (f8).
***CHECK FOR SYSTEM MISSING VALUES AFTER CONVERSION.
**
descriptives v01.
***SET COLUMN WIDTH SOMEWHAT WIDER FOR V01.
**
variable width v01 (6).
***AND SO ON...**就像 Excel-SPSS 转换一样,如 SPSS ALTER TYPE 报告错误值?(SPSS ALTER TYPE Reporting Wrong Values?) 中所述,ALTER TYPE 可能会导致值消失,而没有任何警告或错误。
如果您的转换后的变量没有任何系统缺失值,则表示未发生此问题。但是,如果您 确实 看到一些系统缺失值,最好在继续之前找出发生这些缺失值的原因。
转换有序字符串变量
将有序字符串变量转换为数值变量的简单方法是:
- 对它们进行 AUTORECODE
- 调整答案类别的顺序。
我们已彻底介绍了此方法 SPSS - 使用值标签工具重新编码 (SPSS - Recode with Value Labels Tool)(示例 II)。 务必 查找并尝试它。它可以为您节省大量时间和精力。
如果您无法使用此方法,基本的 RECODE 也可以完成工作,如下所示。
***RECODE STRING VALUES TO NUMBERS.
**
recode v08 to v13
('Very bad' = 1)
('Bad' = 2)
('Neutral' = 3)
('Good' = 4)
('Very Good' = 5)
into n08 to n13.
***SET VALUE LABELS.
**
value labels n08 to n13
1 'Very bad'
2 'Bad'
3 'Neutral'
4 'Good'
5 'Very Good'.
***SET VARIABLE LABELS.
**
variable labels
n08 'How do you rate this course?'
n09 'How do you rate the teacher of this course?'
n10 'How do you rate the lectures of this course?'
n11 'How do you rate the assignments of this course?'
n12 'How do you rate the learning resources (such as syllabi and handouts) that were issued by us?'
n13 'How do you rate the learning resources (such as books) that were not issued by us?'.请记住,编写这样的语法确实很糟糕。
今天就到此为止。如果您有任何问题或意见,请在下面发表评论。
感谢您的阅读!