SPSS – 使用 Python 克隆变量
By Ruben Geert van den Berg under SPSS Python Basics
在本教程中,我们将开发自己的 SPSS Python 模块。你会发现这比你想象的更容易和更高效。我们将使用 hotel-evaluation.sav 数据集,部分内容如下所示。
克隆变量
在使用 RECODE 命令时,我更喜欢将变量重新编码到同一个变量中。那么,如何将新值与旧值进行比较呢?通常,我会先复制一些变量,然后重新编码原始变量。这里的一个问题是,副本没有任何字典信息 (dictionary information)。 我们将通过克隆变量及其所有字典属性来解决这个问题。最终的工具(可在 SPSS Clone Variables Tool 获取)是我最喜欢的工具之一。本教程将介绍它的语法。
RECODE 命令的问题
让我们首先演示 q2 变量的问题。我们将使用下面的语法创建一个副本,并将其与原始变量进行比较。
***在输出中显示变量名、值和标签。***
SET TNUMBERS BOTH TVARS BOTH.
***将 6(“没有回答”)设置为用户缺失值。***
MISSING VALUES q2 (6).
***将 q2 复制到 ori_q2。***
RECODE q2 (ELSE = COPY) INTO ori_q2.
***检查结果。***
CROSSTABS q2 BY ori_q2.结果

APPLY DICTIONARY 命令
我们可以手动为新变量设置所有标签/缺失值/格式等。但是,SPSS 有一个命令可以一次性完成所有操作,那就是 APPLY DICTIONARY 命令。我们将在下面演示它并重新运行表格。
***将所有字典属性从 q2 应用到 ori_q2。***
APPLY DICTIONARY FROM *
/SOURCE VARIABLES = q2
/TARGET VARIABLES = ori_q2.
***现在我们有了一个真正的克隆,我们可以通过运行...来验证。***
CROSSTABS q2 BY ori_q2.
***现在删除新变量,我们需要更好的东西。***
DELETE VARIABLES ori_q2.结果

创建克隆模块
我们在这里使用的 APPLY DICTIONARY 命令一次只能处理一个变量。因此,克隆多个变量仍然很麻烦——至少目前是这样。我们将通过在 Notepad++ 中创建一个模块来加速这一过程。我们首先打开它并将其语言设置为 Python,如下所示。
现在,我们将以下代码添加到我们的模块中(在 Notepad++ 中)。
def clone(varSpec,prefix):
import spssaux
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand(varSpec)
print(varList)这定义了一个名为 clone 的 Python 函数。它还不能工作,但我们将逐步修复它。首先,我们的函数需要知道要克隆哪些变量。我们将通过传递一个名为 varSpec(“变量规范”的缩写)的参数来告诉它。 现在,我们的克隆应该使用哪些名称?一个简单的选择是某个前缀 (prefix) 和原始变量名。我们将把我们的前缀作为第二个参数传递给我们的函数。
将 clone.py 移动到 Site-Packages 文件夹
现在,我们将此文件保存为 clone.py 到某个容易找到的位置(对我来说,是 Windows 的桌面),然后将其移动到 C:\Program Files\IBM\SPSS\Statistics\24\Python\Lib\site-packages 或 site-packages 文件夹所在的任何位置。我们可能会收到一个 Windows 警告,如下所示。只需点击“继续”即可。
导入模块并运行函数
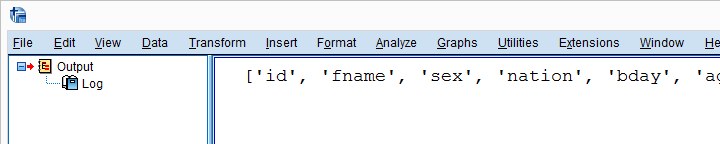
现在我们回到 SPSS 语法编辑器 (Syntax Editor)。我们将导入我们的模块并运行我们的函数,如下所示。注意,它使用 SPSS 的 ALL 关键字指定所有变量,并使用 ori_(“original” 的缩写)作为前缀。
***创建 C:\Program Files\IBM\SPSS Statistics\Python3\Lib\site-packages\clone.py 后,我们将导入它。***
BEGIN PROGRAM PYTHON3.
import clone
clone.clone(varSpec = 'all',prefix = 'ori_')
END PROGRAM.结果
创建新变量名
我们现在将在 Notepad++ 中重新打开 clone.py 并逐步开发它。在每个步骤之后,我们将在 Notepad++ 中保存它,然后在 SPSS 中导入并运行它。让我们首先通过将前缀连接到旧名称来创建我们的新变量名,并打印结果。
clone.py 的新内容 (Notepad++)
def clone(varSpec,prefix):
import spssaux
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand(varSpec)
for var in varList:
newVar = prefix + var # concatenation
print (var, newVar)因为我们已经导入了 clone.py,所以 Python 会忽略任何后续的 import 请求。但是,我们需要“重新导入”我们的模块,因为我们在第一次 import 之后对其进行了更改。因此,我们将使用下面的语法 reload 它。
***从现在开始,每次编辑后重新加载模块。***
BEGIN PROGRAM PYTHON3.
import clone,importlib
importlib.reload(clone)
clone.clone(varSpec = 'all',prefix = 'ori_')
END PROGRAM.结果
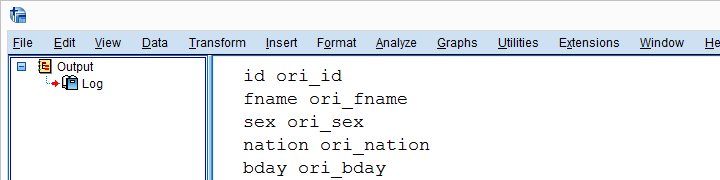
将 RECODE 和 APPLY DICTIONARY 添加到函数
我们现在将让我们的函数创建一个名为 spssSyntax 的空 Python 字符串。在循环遍历我们的变量时,我们将我们的 SPSS 语法连接到它。 我们将添加到其中的语法基本上就是我们之前使用的 RECODE 和 APPLY DICTIONARY 命令。我们将旧变量名称的所有实例替换为 %(var)s。%(newVar)s 是我们新变量名称的占位符。这在 SPSS Python Text Replacement Tutorial 中进行了解释。
clone.py 的新内容 (Notepad++)
def clone(varSpec,prefix):
import spssaux
spssSyntax = '' # empty string for concatenating to
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand(varSpec)
for var in varList:
newVar = prefix + var
# three quotes below because line breaks in string
spssSyntax += '''
RECODE %(var)s (ELSE = COPY) INTO %(newVar)s.
APPLY DICTIONARY FROM *
/SOURCE VARIABLES = %(var)s
/TARGET VARIABLES = %(newVar)s.
'''%locals()
print(spssSyntax)就像之前一样,我们重新加载我们的模块并使用下面的语法运行我们的函数。
***从现在开始,每次编辑后重新加载模块。***
BEGIN PROGRAM PYTHON3.
import clone,importlib
importlib.reload(clone)
clone.clone(varSpec = 'all',prefix = 'ori_')
END PROGRAM.结果
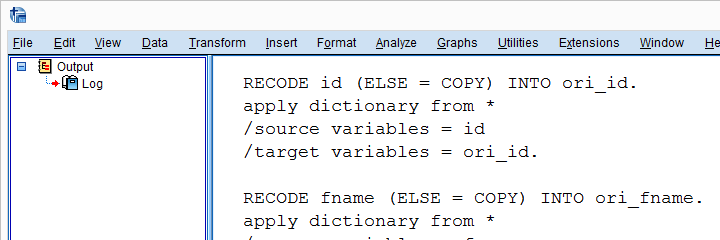
检查字符串变量
我们的语法看起来很棒,但有一个问题:我们的 RECODE 命令将在字符串变量上崩溃。我们首先需要使用类似 STRING ori_fname (A18) 的命令来声明它们。我们可以使用 sDict[var].VariableType 检测字符串变量及其长度。对于字符串变量,这将返回字符串长度,对于数值变量,则返回 0。让我们试试看。
clone.py 的新内容 (Notepad++)
def clone(varSpec,prefix):
import spssaux
spssSyntax = ''
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand(varSpec)
for var in varList:
newVar = prefix + var
varTyp = sDict[var].VariableType # 0 = numeric, > 0 = string length
print(var,varTyp)
spssSyntax += '''
RECODE %(var)s (ELSE = COPY) INTO %(newVar)s.
APPLY DICTIONARY FROM *
/SOURCE VARIABLES = %(var)s
/TARGET VARIABLES = %(newVar)s.
'''%locals()
print(spssSyntax)(与之前一样,在 SPSS 中重新加载并运行。)
结果
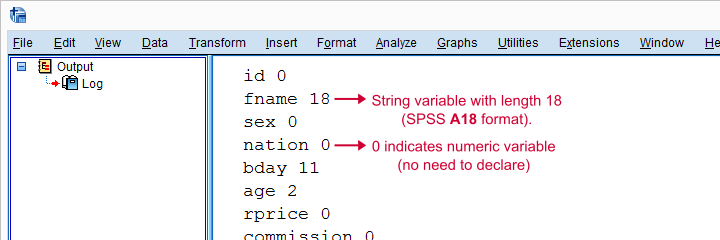
在 RECODE 之前声明字符串
对于我们指定的每个字符串变量,我们现在将相应的 STRING 命令添加到我们的语法中。
def clone(varSpec,prefix):
import spssaux
spssSyntax = ''
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand(varSpec)
for var in varList:
newVar = prefix + var
varTyp = sDict[var].VariableType # 0 = numeric, > 0 = string length
if varTyp > 0: # need to declare new string variable in SPSS
spssSyntax += 'STRING %(newVar)s (A%(varTyp)s).'%locals()
spssSyntax += '''
RECODE %(var)s (ELSE = COPY) INTO %(newVar)s.
APPLY DICTIONARY FROM *
/SOURCE VARIABLES = %(var)s
/TARGET VARIABLES = %(newVar)s.
'''%locals()
print(spssSyntax)运行所有 SPSS 语法
在这一点上,我们可以使用我们的克隆函数:我们将注释掉我们的 print 语句并将其替换为 spss.Submit 以运行我们的语法。正如我们将看到的,Python 现在创建了我们指定的所有变量的完美克隆。
def clone(varSpec,prefix):
import spssaux,spss # spss module needed for submitting syntax
spssSyntax = ''
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand(varSpec)
for var in varList:
newVar = prefix + var
varTyp = sDict[var].VariableType
if varTyp > 0:
spssSyntax += 'STRING %(newVar)s (A%(varTyp)s).'%locals()
spssSyntax += '''
RECODE %(var)s (ELSE = COPY) INTO %(newVar)s.
APPLY DICTIONARY FROM *
/SOURCE VARIABLES = %(var)s
/TARGET VARIABLES = %(newVar)s.
'''%locals()
spssSyntax += "EXECUTE." # execute RECODE (transformation) commands
#print(spssSyntax) # comment out, uncomment if anything goes wrong
spss.Submit(spssSyntax) # have Python run spssSyntax最后的说明
我们的克隆函数工作正常,但我们还可以添加一件事:检查新变量是否已经存在。由于今天的课程可能已经有些挑战性了,我们将把它作为留给读者的练习。