SPSS:使用 Python 创建新文件
本教程将指导你如何使用 SPSS 和 Python,根据课程评估数据中的不同专业,为每个专业创建单独的 Excel 文件。
1. 背景
一位老师进行了一次课程评估,数据以 SPSS 格式存储在 course-evaluation.sav 文件中。来自不同专业的学生参与了评估,现在教务主任希望为每个专业创建单独的 Excel 文件。使用 SPSS 和 Python 可以非常方便地实现这个目标。
2. 将 SPSS 数据保存为 Excel 文件
首先,我们需要生成将所有数据保存为单个 Excel 文件的 SPSS 语法。从 SPSS 菜单栏中,选择 文件(F) 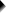 另存为(S)…,并按照下图填写:
另存为(S)…,并按照下图填写:
这将生成以下 SPSS 语法:
* 保存所有个案为 Excel 文件(从菜单粘贴).
SAVE TRANSLATE OUTFILE='D:\data\course_evaluation.xlsx'
/TYPE=XLS
/VERSION=12
/FIELDNAMES
/CELLS=LABELS
/REPLACE.3. 选择要保存的个案
之前的语法会将所有个案(即所有专业)保存到一个 Excel 文件中。现在,我们需要只保存个案的子集——一次保存一个专业。可以使用 SELECT IF 命令,并在其前面加上 TEMPORARY。我们可以复制、粘贴和编辑语法,为每个专业生成一个。这里我们将用 Python 来完成这个任务。首先,我们需要将研究专业转换为 SPSS 字符串变量,使用以下语法:
* 创建 SPSS 字符串变量,用于保存专业的 Value Label.
STRING smajor (A20).
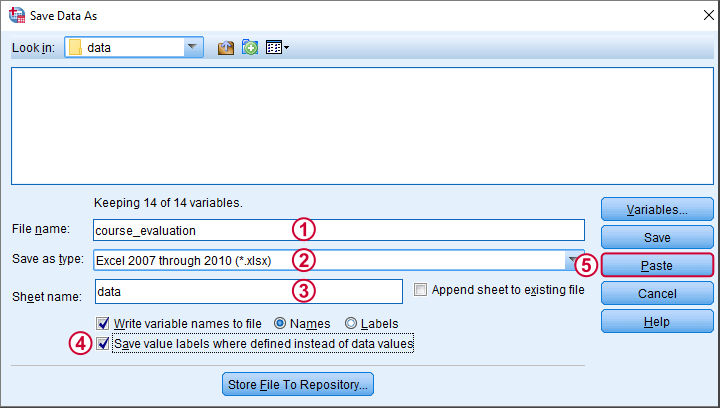
COMPUTE smajor = VALUELABEL(major).
CROSSTABS major BY smajor.结果
4. 使用 Spssdata 查找数据值
spssdata 是一个 Python SPSS 模块,专门用于查找数据值。使用起来非常简单,如下面的语法所示。需要注意的是,spssdata 的大小写是敏感的,必须使用 spssdata. **S** pssdata 。
* 查找并报告 smajor 中的所有 SPSS 数据值.
BEGIN PROGRAM PYTHON3.
import spssdata
for case in spssdata.Spssdata('smajor'):
print(case)
END PROGRAM.结果
5. 清理专业数据
Python 会为每个个案返回一个元组 (tuple),其中包含学生的专业,类型为 Python string。我们首先需要从每个元组中提取第一个(也是唯一的)元素,通过在元组后面加上 [0] 来实现,如下所示。
请注意,每个专业的右侧都用空格填充,总长度为 20。这是因为 SPSS 中的 variable format 是 A20。在 Python 中,我们将使用 strip() 方法删除这些空格。
* 从元组中获取 Python 字符串值并删除空格.
BEGIN PROGRAM PYTHON3.
import spssdata
for case in spssdata.Spssdata('smajor'):
print(case[0].strip())
END PROGRAM.6. 去重专业数据
此时,Python 以一种良好且干净的方式检索所有专业。但由于我们只需要为每个 不同的 专业创建一个 Excel 文件,因此我们需要对这些数据进行去重。首先,我们创建一个空的 Python 列表对象。然后,我们只在列表中还不存在该专业时,才将该专业添加到列表中。
* 创建一个 Python 列表,用于保存 smajor 中的所有不同值.
BEGIN PROGRAM PYTHON3.
import spssdata
majors = []
for case in spssdata.Spssdata('smajor'):
major = case[0].strip()
if major not in majors:
majors.append(major)
print(majors)
END PROGRAM.结果

7. 创建并检查 SPSS 语法
我们得到的不重复专业名称的 Python 列表看起来不错!如果想确保数据的准确性,可以在 SPSS 中运行 FREQUENCIES SMAJOR. 命令,确认 这些确实是数据中的专业。现在我们已经完成了准备工作,接下来我们将创建实际的 SPSS 语法。
下面的语法首先创建一个空的 Python 字符串。接下来,我们将循环遍历不同的专业,并将之前从菜单中创建的一些 SPSS 语法连接到该字符串。在这个语法中,我们添加了 %s,它用于 Python 文本替换。结果将是一大块 SPSS 语法,我们首先会检查它。
* 为 majors 中的每个值创建 SPSS SAVE TRANSLATE 命令.
BEGIN PROGRAM PYTHON3.
spssSyntax = ''
for major in majors:
spssSyntax += '''
TEMPORARY.
SELECT IF (smajor = '%s').
SAVE TRANSLATE OUTFILE='D:\data\course_evaluation_%s.xlsx'
/TYPE=XLS
/VERSION=12
/FIELDNAMES
/CELLS=LABELS
/REPLACE.
'''%(major,major.lower())
print(spssSyntax)
END PROGRAM.结果
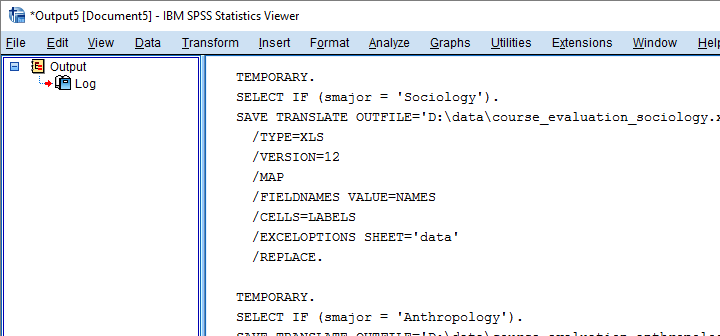
8. 运行 SPSS 语法
既然语法看起来没问题,我们可以使用 spss.Submit 运行它。为了使用这个函数,我们还需要导入 spss 模块,因为我们到目前为止还没有这样做。
* 运行我们刚刚创建并检查过的语法.
BEGIN PROGRAM PYTHON3.
import spss
spss.Submit(spssSyntax)
END PROGRAM.结果
9. 总结
总而言之,Python 可以很容易地使用 spssdata.Spssdata() 查找数据值。通过在括号中指定变量名,将其限制为单个变量。将括号留空会查找所有变量的数据值。一旦我们在 Python 中获得了数据值,我们就可以将它们插入到 SPSS 语法中,或者用它们做很多其他事情。
感谢阅读!