从字符串变量中提取数字
作者:Ruben Geert van den Berg,发表于 SPSS 字符串变量
- 检查频率表
- 提取前导数字
- 检查哪些值无法转换
- 检查最终结果
最近,我们的一位客户使用文本字段来询问受访者的年龄。由此产生的年龄变量存储在 age-in-string.sav 文件中,部分内容如下所示。
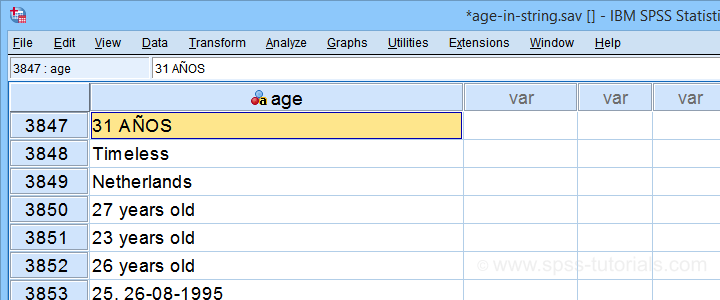
我希望你意识到这看起来很糟糕:
age是一个字符串变量,所以我们无法计算它的均值、标准差或任何其他统计量;- 我们无法轻易地将
age转换为数值变量,因为它包含的不仅仅是数字; - 简单的文本替换无法删除所有此类不需要的字符。
更糟糕的是,数据包含 3,895 个案例,因此手动操作是不可行的。不过,我们将快速解决这个问题。
检查频率表
首先,让我们看看我们正在处理哪些有问题的值。因此,让我们使用下面的 语法 (syntax) 运行一个基本的频率表。
***检查 age (字符串) 中存在哪些值。
**
frequencies age
/format dfreq.结果
如果我们将表格向下滚动一点,我们将看到一些有问题的值,如下所示。
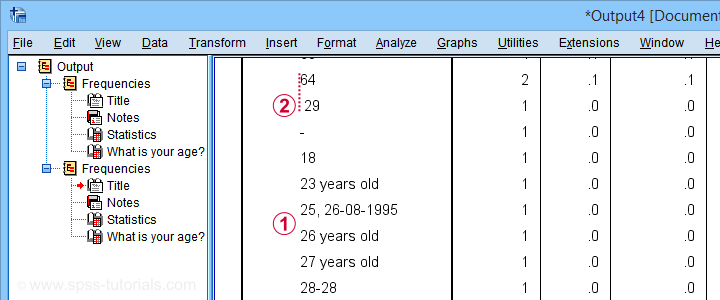
此表向我们展示了 2 个重要信息:
 大多数可以纠正的值都以 2 位数字开头;
大多数可以纠正的值都以 2 位数字开头;  至少有一个值前面有一个前导空格。
至少有一个值前面有一个前导空格。
让我们首先删除任何前导空格。我们将通过运行 compute age = ltrim(age) 来简单地做到这一点。
提取前导数字
我们现在将使用以下语法从我们的 字符串变量 (string variable) 中提取任何前导数字。
***创建长度为 3 的新字符串变量 nage - 假设没有人超过 999 岁...
** string nage (a3).
***循环 age 中的字符,如果它们是数字,则传递到 nage 中。
** loop #ind = 1 to char.length(age).
do if(char.index('0123456789',char.substr(age,#ind,1)) > 0).
compute nage = concat(rtrim(nage),char.substr(age,#ind,1)).
else.
break.
end if.
end loop.
execute.所以我们在这里所做的基本上是:
- 我们创建一个新的字符串变量
nage; - 我们
LOOP遍历age中的所有字符; - 我们评估每个字符是否为数字:如果该字符在 ‘0123456789’ 中找不到,
char.index返回 0。 - 如果该字符是一个数字(DO IF),我们将它添加到新字符串变量的末尾;
- 如果该字符不是一个数字(
ELSE),BREAK结束该特定受访者的循环。
最后一个条件对于诸如 “55 and will become 56 on 3/9” 之类的值是必需的。我们需要确保在 “55” 之后 没有数字添加到我们的新变量中。否则,我们将得到 “555639”——一个也许只有 Fred Flintstone 才可能拥有的年龄。
检查哪些值无法转换
现在让我们检查哪些原始 age 值无法转换。我们将重新运行我们的频率分布,但我们将它限制为新 age 值仍然为空的受访者。
***仅在下一个表中包含没有 nage 的受访者。
**
temporary.
select if (nage = '').
***检查哪些 age 值尚未转换。
**
frequencies age
/format dfreq.结果
令人惊讶的是,快速向下滚动我们的表格显示,我们只能合理地转换一个未转换的 age 值:“Will become 56 on the 3rd of September:-)”
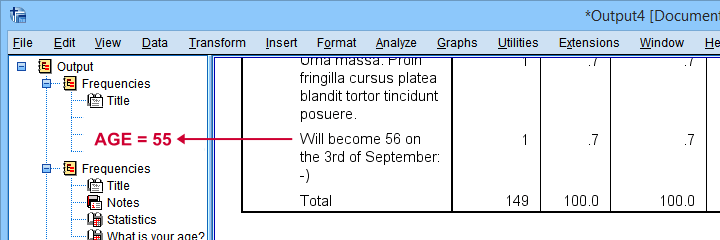
从这个陈述中推断出这个人完成问卷调查时是 55 岁可能是安全的。我们将使用一个简单的 IF 命令将其年龄设置为 55。然后我们将运行一个快速的最终检查。
***手动纠正单个年龄值。
**
if(char.index(age,'Will become 56') > 0) nage = '55'.
***重新检查哪些 age 值尚未转换。
**
temporary.
select if (nage = '').
frequencies age
/format dfreq.最终频率表
如下所示,我们最小的更正导致仅有 148 个(在 3,895 个中)未转换的年龄。快速向下滚动我们的表格显示,没有其他可能的转换。
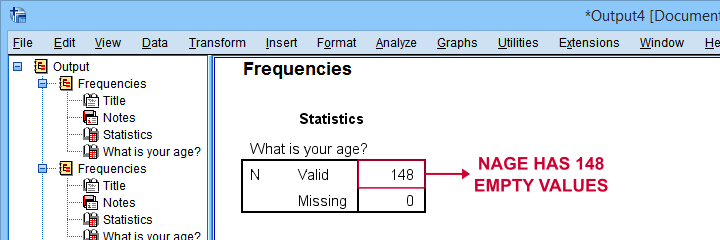
我们现在将使用 ALTER TYPE 将我们的新 age 变量转换为数值型,并检查结果。
***将 nage 转换为数值型。
**
alter type nage(f3).
***检查年龄分布。
**
frequencies nage
/histogram.
***从所有分析和/或编辑中排除 nage = 99。
**
missing values nage (99).检查最终结果
首先,请注意我们的最终 age 变量有 N = 148 个 缺失值 (missing values) ——正如预期的那样。检查这一点很重要,因为 ALTER TYPE 可能会导致缺失值,而不会抛出任何错误或警告。
接下来,下面显示了我们最终 age 值的直方图。
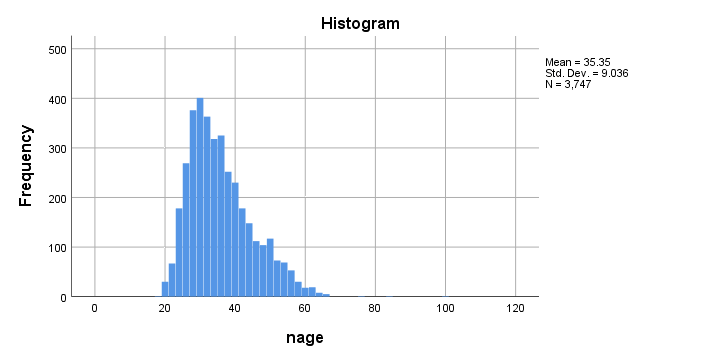
尽管年龄分布看起来是合理的,但 x 轴的范围高达 120 岁。SPSS 通常在两侧应用 20% 的边距,因此这可能表明年龄在 100 岁左右。
仔细检查显示有人报告的年龄为 99 岁。由于我们认为这对于当前的研究来说是不合理的,因此我们将其设置为用户缺失值。
完成。