SPSS – 打开 CSV 数据文件
作者:Ruben Geert van den Berg,发表于 SPSS Blog
概要
本教程将引导你如何在 SPSS 中打开 .csv 数据文件。我们选择了一个从 Google Analytics (GA) 获取的 .csv 文件作为示例。考虑到许多读者可能不熟悉 GA,下面的截图展示了数据在导出为 .csv 文件之前的基本形态。
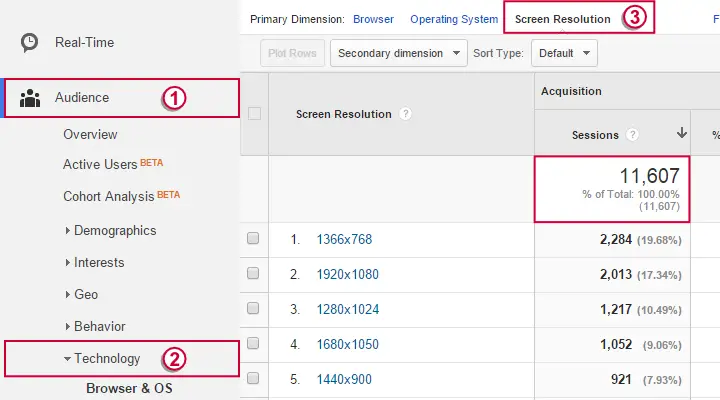
原始数据文件(由 GA 生成)可以从 这里 下载。之所以选择这个文件,是因为在 SPSS 中打开它会遇到一些你在实际数据中经常遇到的问题。我们将花时间解释并解决这些问题。
Notepad++
好的,我们从哪里开始呢?通常,.csv 文件与 MS Excel 或 OpenOffice Calc 等电子表格编辑器相关联。但是,更好的方法是使用 Notepad++ 或类似的文本编辑器检查该文件。我们马上就会看到,这使我们能够收集有关文件内容的一些重要信息。下面的屏幕截图显示了数据在 Notepad++ 中的样子。
CSV 文件的内容
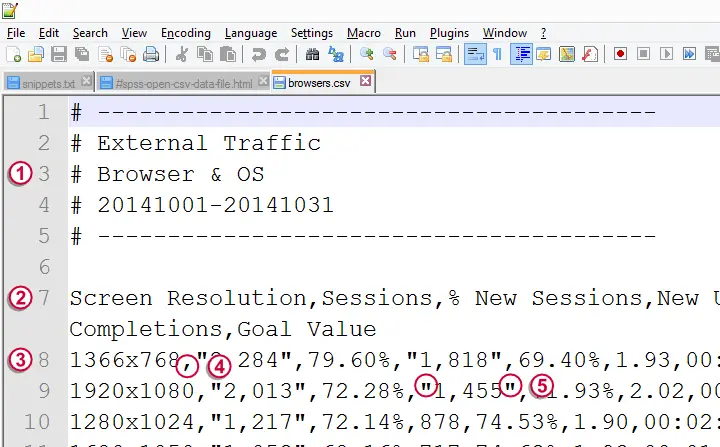
 请注意,文件的前 6 行是对数据的基本描述。在检查完数据的其余部分后,我们将删除它们。
请注意,文件的前 6 行是对数据的基本描述。在检查完数据的其余部分后,我们将删除它们。  第 7 行包含变量名。请注意,其中大多数变量名不适用于 SPSS,因为它们包含空格或以百分号开头。我们将手动清理它们。
第 7 行包含变量名。请注意,其中大多数变量名不适用于 SPSS,因为它们包含空格或以百分号开头。我们将手动清理它们。  实际数据从第 8 行开始,删除前 6 行后,这将是数据的第二行。
实际数据从第 8 行开始,删除前 6 行后,这将是数据的第二行。  注意数据值是如何用逗号分隔的(因此称为“逗号分隔值”,即
注意数据值是如何用逗号分隔的(因此称为“逗号分隔值”,即 .csv 文件)。这些逗号被称为分隔符 (delimiter)。  如果一个值包含逗号,则它会被双引号引起来。这就是文本限定符 (text qualifier)。这些引号表示它们之间的逗号不应被视为分隔符。
如果一个值包含逗号,则它会被双引号引起来。这就是文本限定符 (text qualifier)。这些引号表示它们之间的逗号不应被视为分隔符。
更多 CSV 文件的内容
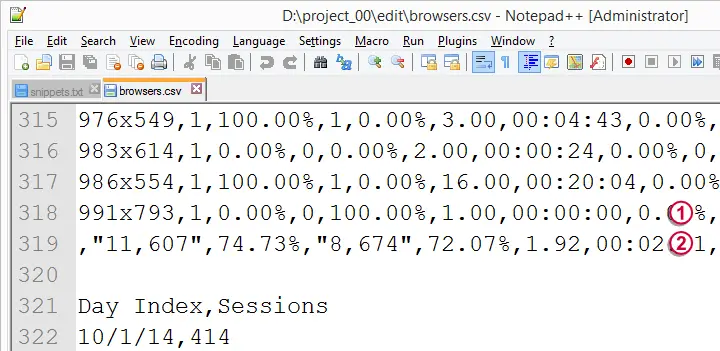
如果我们快速向下滚动文件(提示:使用键盘上的 pgdn 键),我们会看到第 318 行是包含原始数据值的最后一行。 第 319 行及以下包含我们不需要的汇总统计信息。因此,我们将删除它们。

最后但同样重要的是,请注意状态栏中的“UTF-8”。这是文件编码 (encoding)。它基本上告诉我们如何将字符映射到文件实际包含的位(1 和 0)。
清理 CSV 文件
现在,我们像刚才讨论的那样清理 .csv 文件。完成此操作后,我们将使用不同的文件名保存它。这使我们能够将手动编辑的文件与 GA 生成的原始文件进行比较。我们将在 SPSS 中打开的最终 .csv 文件可以从 browsers.csv 下载。
在 SPSS 中打开 CSV 文件
我们现在准备好在 SPSS 中打开我们的 .csv 文件。为此,我们首先启动 SPSS,然后导航到 F 文件 (File)  O 打开 (Open) D 数据 (Data) 。
O 打开 (Open) D 数据 (Data) 。
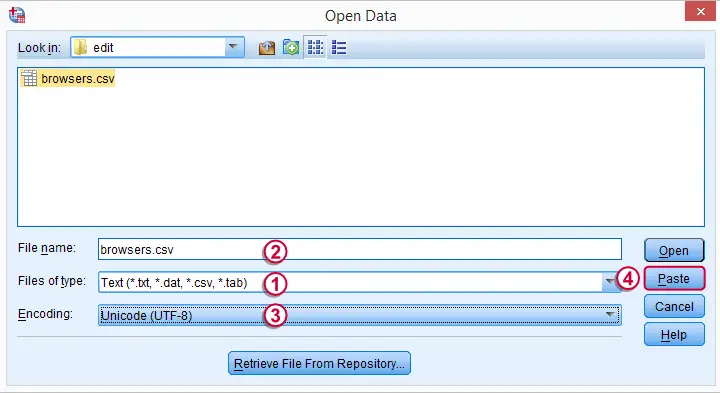
我们在 Notepad++ 中看到文件编码是 UTF-8。当我们选择文件时,SPSS 可能会在此处切换到“本地编码 (Local Encoding)”。如果发生这种情况,请在继续之前将其设置回 UTF-8。 单击 P 粘贴 (Paste) 而不是 O 打开 (Open) 。
步骤 1
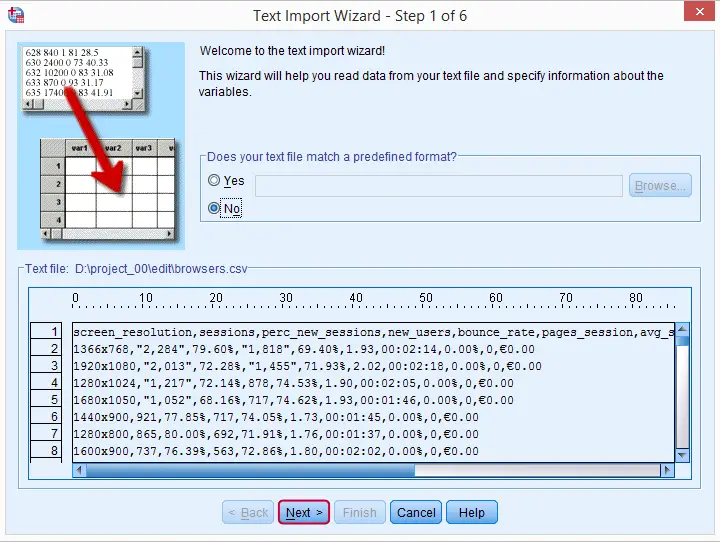
步骤 2
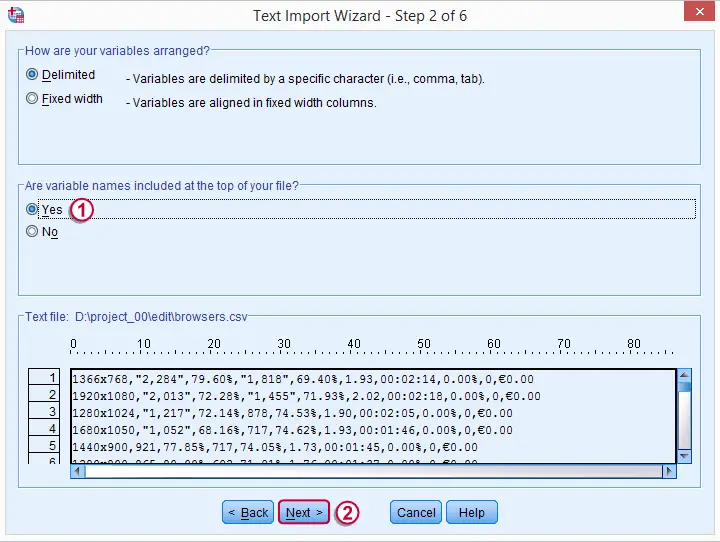
请记住,变量名构成了 .csv 文件的第一行。
步骤 3
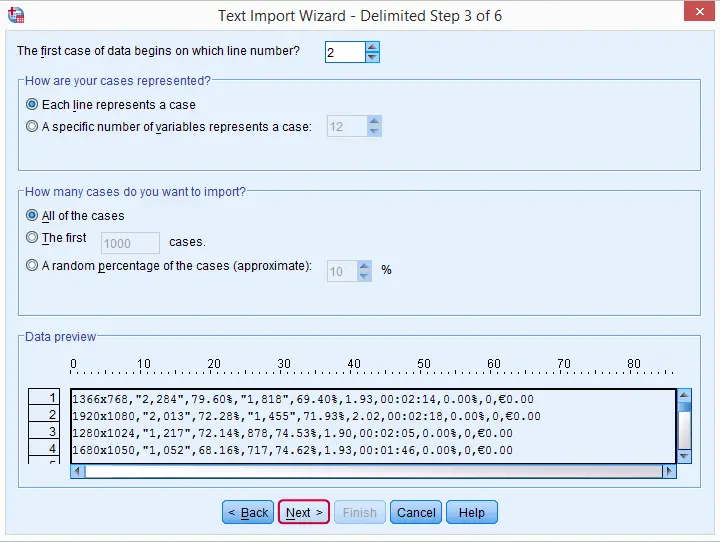
步骤 4
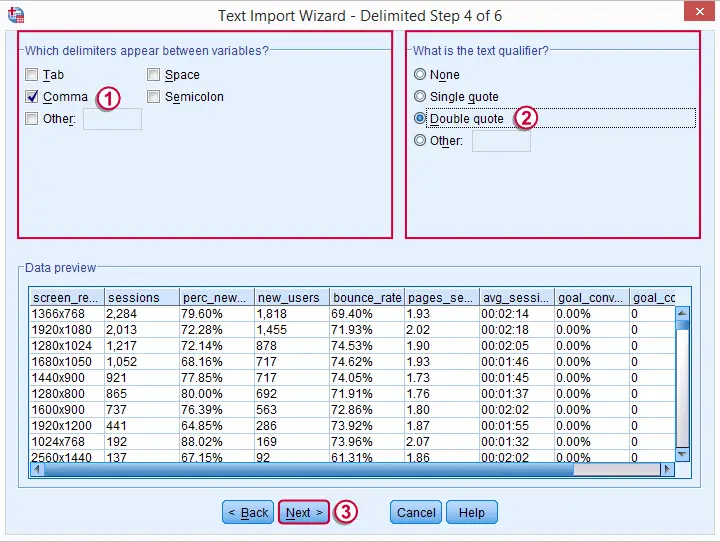
在这里,我们指定在 Notepad++ 中检查文件时识别出的分隔符 (delimiter)。 就像我们之前看到的那样,我们原始数据中唯一的文本限定符 (text qualifier) 是双引号。
步骤 5
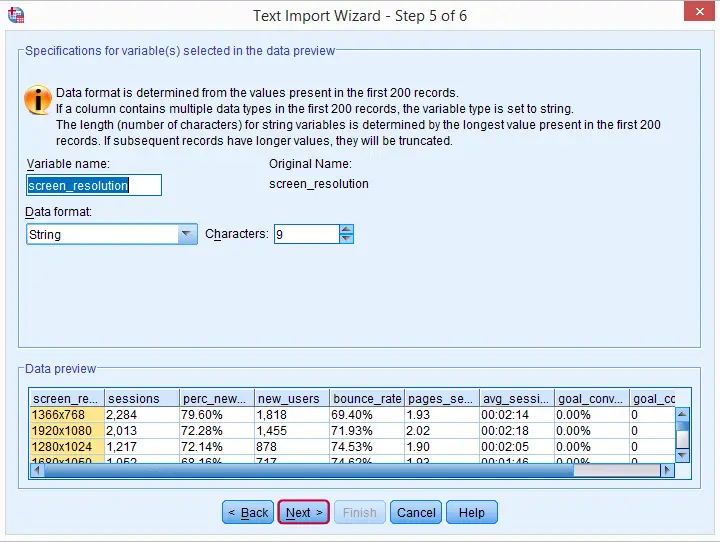
我们_可以_在此处指定一些变量格式 (variable formats)。但是,稍后处理会更快、效果更好。
步骤 6
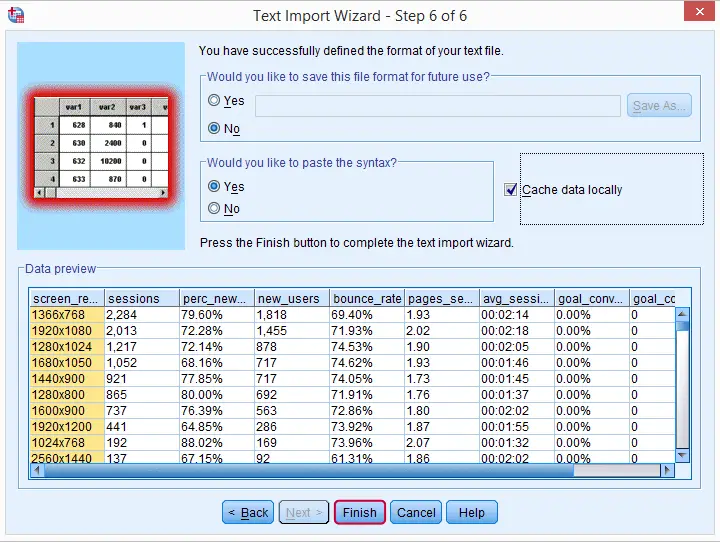
初始语法
按照前面的步骤将生成以下语法 (syntax)。想要从本教程复制粘贴语法的读者可以更正 /FILE 规范(语法的第二行),或者创建一个文件夹 d:/project_00/edit 并将 browsers.csv 移动到此文件夹中。 在运行此语法之前,我们删除最后一行;我们没有请求任何 DATASET NAME ... 命令,运行它只会妨碍我们。
***从菜单粘贴的初始语法 - 需要进行一些更正。
**
GET DATA /TYPE=TXT
/FILE="D:\project_00\edit\browsers.csv"
/ENCODING='UTF8'
/DELCASE=LINE
/DELIMITERS=","
/QUALIFIER='"'
/ARRANGEMENT=DELIMITED
/FIRSTCASE=2
/IMPORTCASE=ALL
/VARIABLES=
screen_resolution A9
sessions F5.0
perc_new_sessions A7
new_users F5.0
bounce_rate A7
pages_session F4.2
avg_session_duration A8
goal_conversion_rate A5
goal_completions F1.0
goal_value A7.
CACHE.
EXECUTE.
DATASET NAME DataSet1 WINDOW=FRONT.系统缺失值
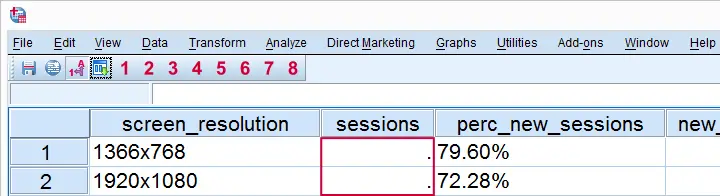
运行语法后,让我们看一下 数据视图 (data view)。请注意,sessions 中存在一些 系统缺失值 (system missing values)。原因是某些值包含逗号。如果我们仔细查看语法,我们会看到它包含 sessions F5.0。这意味着变量 sessions 的值是根据 F 格式(标准数值型)解释的,该格式无法识别逗号。解决方案是将此行替换为 sessions comma6。我们对所有标准数值型变量都这样做。如果您不确定这指的是哪些变量,请不要担心;我们稍后会提供完整的更正后的语法。
字符串变量
其他变量起初看起来可能不错,但检查 变量视图 (variable view) 显示其中许多变量是 字符串变量 (string variables)。如果我们仔细考虑数据,我们会得出结论,screen_resolution 应该是这里唯一的字符串变量。
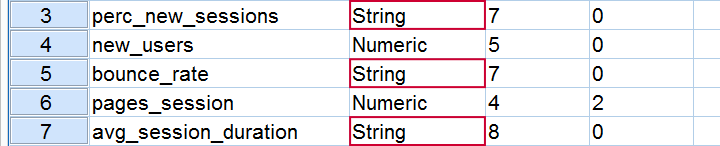
这是与我们之前看到的系统缺失值相同的问题 - 以及相同的解决方案。例如,我们在语法中找到 perc_new_sessions A7。A 格式 表示字符串变量,SPSS 在此处选择此格式是因为数据中存在百分号。解决方案是将该行替换为 perc_new_sessions pct7.2。类似地,我们为所有百分比变量选择此格式。同样,我们稍后会提供完整的更正后的语法。
时间变量
我们的数据包含一个时间变量:avg_session_duration。我们的语法将其寻址为 avg_session_duration A8。我们的时间值采用 hh:mm:ss 格式。在 SPSS 中,这是 time8 格式(其中 8 表示字符数,包括冒号)。因此,我们将前一行替换为 avg_session_duration time8。
最终更正后的语法
在进行所有修改后,我们最终得到以下语法。这是我们将用于在 SPSS 中打开 .csv 文件的最终语法。
***更正后的语法。适用于除 goal_value 之外的所有变量。
**
GET DATA /TYPE=TXT
/FILE="D:\project_00\edit\browsers.csv"
/ENCODING='UTF8'
/DELCASE=LINE
/DELIMITERS=","
/QUALIFIER='"'
/ARRANGEMENT=DELIMITED
/FIRSTCASE=2
/IMPORTCASE=ALL
/VARIABLES=
screen_resolution A9
sessions comma6
perc_new_sessions pct7.2
new_users comma6
bounce_rate pct7.2
pages_session F4.2
avg_session_duration time8
goal_conversion_rate pct7.2
goal_completions F1.0
goal_value A7.
CACHE.
EXECUTE.欧元符号
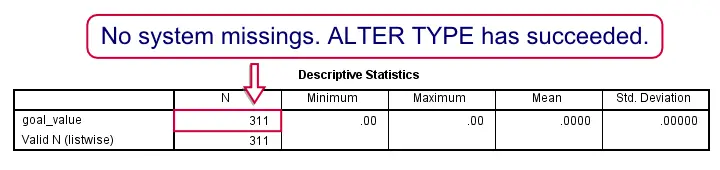
细心的读者可能会注意到,我们没有阻止 goal_value 最终成为字符串变量。这是因为之前的步骤无法阻止这种情况。为了完整起见,我们将使用以下语法修复它。 正如在其他地方解释的那样,我们始终确保 ALTER TYPE 不会创建任何系统缺失值。我们在第 3 步中这样做。
用于修复欧元符号的语法
***1. 删除前导欧元符号。
**
compute goal_value = char.substr(goal_value,2).
execute.
***2. 转换为数值变量。
**
alter type goal_value(f4.2).
***3. 确认所有 311 个值均不缺失。
**
descriptives goal_value.
***4. 将 cca(自定义货币 A)设置为欧元。
**
set cca '-,€ ,,'.
***5. 将 goal_value 设置为 cca。
**
formats goal_value(cca6.2).
***完成。**结果
提取屏幕宽度
就是这样。我们现在有一个完美的 SPSS 文件,其中包含我们的 .csv 数据。如果这就是您想知道的全部内容,那么您可以立即停止阅读。
好的,请注意 screen_resolution 的值由两个数字组成,中间用 x 分隔。第一个数字是屏幕宽度(以像素为单位),我们将通过运行以下语法来提取它。
***1. 计算 "x" 的位置。
**
compute pos_x = char.index(screen_resolution,'x').
execute.
***2. 创建新的空字符串变量。
**
string width(a5).
***3. 计算 width = screen_resolution 中直到 "x" 位置的字符。
**
compute width = char.substr(screen_resolution,1,pos_x - 1).
execute.
***4. 将 width 更改为数值变量。
**
alter type width(f5).
***5. 确保 ALTER TYPE 不会创建系统缺失值。
**
descriptives width.
***完成。**每个屏幕宽度的会话累积百分比
最后。我们准备好创建我们想要的表格:我们想知道每个屏幕宽度的会话累积百分比,从最大到最小。请注意,大多数情况代表许多会话。为了让 SPSS 将每种情况解释为它所代表的会话数,我们将使用 WEIGHT,如下所示。 最后,我们将运行一个 FREQUENCIES 表,我们将根据屏幕宽度降序对其进行排序。
用于累积百分比的 SPSS 语法
***1. 使每个记录都计为它所代表的会话数。
**
weight by sessions.
***2. 创建频率表,按宽度降序排序。
**
frequencies width/format dvalue.校验和

由于加权了我们的案例,SPSS 报告了 11,607 个案例。这与我们在 Google Analytics (GA) 界面中看到的会话数(第一个屏幕截图)完全相同。我们可以将其视为校验和:这些数字相同强烈表明我们的 SPSS 数据与原始 GA 数据完全对应。
目的
本研究的目的是选择我们的网站设计应支持的最小屏幕宽度。由于我们网站的性质,很少有访问者使用较小的屏幕宽度(智能手机或平板电脑)。我们是否应该投资支持移动设备而不是编写更多教程?我们的最终表格表明我们不应该这样做。
结论
 最终表格中最有趣的部分
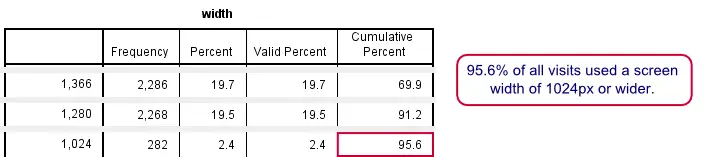
最终表格中最有趣的部分
第二个表格相当大,但这不会困扰我们。如果我们检查累积百分比并向下滚动,我们会得出结论,69.9% 的会话使用了 1,366 像素或更高的屏幕宽度。至少 1,280 像素的屏幕宽度用于所有会话的 91.2%。 最后,如果我们确保我们的网站在 1,024 像素或更高的屏幕宽度下运行良好,我们将支持所有访问的 95.6%。我们的最终决定是支持 800 像素或更高的屏幕宽度,因为这是我们的设计可以合理处理的最小宽度。