SPSS:使用 Python 删除选定的变量
作者:Ruben Geert van den Berg,归属于SPSS Python 基础
多变量分析经常受到缺失值的影响。一个常见的策略是首先删除具有较高缺失值百分比的变量和个案。然后,我们有时会使用成对缺失值删除或填补它们。
现在,要查找具有大量缺失值的变量,您可以:
- 确保您指定了 用户缺失值 (user missing values);
- 运行一个简单的 DESCRIPTIVES 表;
- 检查哪些变量的 N 相对较低;
- 输入一个包含这些变量名的 DELETE VARIABLES 命令并运行它。
现在,如果您有大量的变量,或者您经常在不同的文件上运行这些步骤,您可能希望尝试自动化它们。本课程展示了如何在 many-missings.sav 上执行此操作,其部分内容如下所示。
检查个案计数
找到数据中个案数量的一个非常简单的方法 - 忽略任何 WEIGHT (权重)、FILTER (筛选) 或 SPLIT FILE (拆分文件) 设置 - 是通过按 ctrl 和  移动到最后一个个案,并检查其个案编号。
我们的数据包含 100 个个案。顺便说一下,获得此数字的另一种方法是运行 SHOW N。
运行基本的描述性统计表
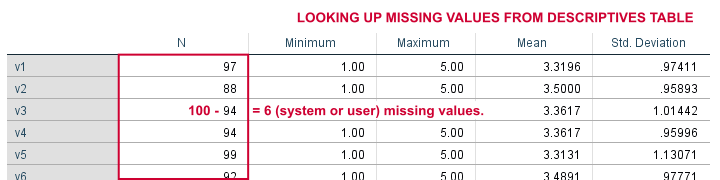
对于手头的数据,已经设置了用户缺失值。我们现在将遵循非 Python 方法的一部分,并运行一个基本的描述性统计表,使用 DESCRIPTIVES v1 TO v20。由于我们有 100 个个案,(100 - N)是每个变量中缺失值的数量。我们将此表的屏幕截图保存在 Irfanview 或其他程序中。
查找单个变量中的所有值
我们首先使用以下语法简单地查找第一个变量 v1 中的所有值。
***查找变量中的所有数据值。**
begin program python3.
import spssdata
with spssdata.Spssdata("v1") as allData: # 包含 v1 的所有值
for case in allData: # 对于我们数据中的 100 个案例
print(case)
end program.结果
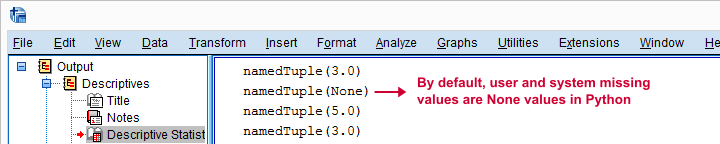
首先,Python 将每个个案作为 namedTuple 返回,因为它可能包含多个值。在本例中,它没有,因为我们只指定了一个变量。我们可以使用 case[0] 从元组中提取第一个也是唯一一个值,我们将在稍后这样做。
其次,默认情况下,系统缺失值和用户缺失值都会导致 None。因此,我们可以通过计算变量拥有的 None 值的数量来获得变量的缺失值数量。我们将在下一个语法示例中对 v2 执行此操作。
计算单个变量中的 None 值
***计算变量中的(系统和用户)缺失值。**
begin program python3.
import spssdata
with spssdata.Spssdata("v2") as allData:
misCnt = 0 # 缺失值最初为 0
for case in allData:
if case[0] is None: # 系统或用户缺失值
misCnt += 1 # 将 1 添加到缺失值
print(misCnt)
end program.这将返回 12。我们的 DESCRIPTIVES 表确认 v2 具有 (100 - 12 = ) 88 个有效值。
展开变量范围
您可能并不总是想循环遍历_所有_变量,而是想要循环遍历使用 TO 指定的相邻变量范围。在本例中,我们将让 Python 使用以下语法展开 v1 TO v20。这将返回一个变量名 Python 列表对象,我们将在稍后循环遍历。
***展开变量范围。**
begin program python3.
import spssaux
sDict = spssaux.VariableDict(caseless = True) # 允许变量名的大小写错误
varList = sDict.expand("v1 to v20")
print(varList)
end program.查找每个变量的缺失值
在创建目标变量列表后,我们将循环遍历它并计算每个变量中的 None 值。就像这样,下面的语法基本上结合了我们到目前为止在本课程中介绍的语法片段。我们首先只打印每个变量名及其缺失值的数量。同样,我们可以使用我们的 DESCRIPTIVES 表验证整个结果。
***报告每个变量中的缺失值数量。**
begin program python3.
import spssaux,spssdata
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand("v1 to v20")
for var in varList: # 循环遍历 v1 到 v20
with spssdata.Spssdata(var) as allData:
misCnt = 0 # = 每个变量的缺失值计数
for case in allData:
if case[0] is None: # = 缺失值
misCnt += 1 # 将 1 添加到计数器
print(var,misCnt) # 使用 DESCRIPTIVES 表验证
end program.结果
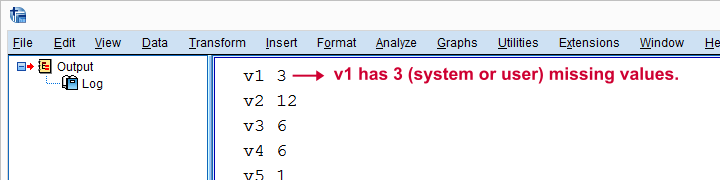
创建 SPSS DELETE VARIABLES 语法
我们选择删除所有包含 15 个或更多缺失值的变量。我们将创建一个名为 spssSyntax 的 Python 字符串,该字符串最初只包含 DELETE VARIABLES。然后,我们将连接每个 misCnt >= 15 的变量和一个空格到它。最后,我们将句点添加到我们的 SPSS 命令并检查它。
***创建和检查语法。**
begin program python3.
import spssaux,spssdata,spss
spssSyntax = "DELETE VARIABLES "
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand("v1 to v20")
for var in varList:
with spssdata.Spssdata(var) as allData:
misCnt = 0
for case in allData:
if case[0] == None:
misCnt += 1
if misCnt >= 15: # 变量至少有 15 个缺失值
spssSyntax += var + ' ' # 将变量名添加到 DELETE VARIABLES
print(spssSyntax + ".") # 将句点添加到命令
end program.删除变量
由于我们的 DELETE VARIABLES 命令看起来很棒,我们基本上就在那里了;我们将注释掉 print 语句,并将其替换为 spss.Submit,以便让 Python 运行我们的 SPSS 语法。由于这需要 spss 模块,我们需要将其添加到我们的 import 命令(下面的第 4 行)。
***创建并运行语法。**
begin program python3.
import spssaux,spssdata,spss
spssSyntax = "DELETE VARIABLES "
sDict = spssaux.VariableDict(caseless = True)
varList = sDict.expand("v1 to v20")
for var in varList:
with spssdata.Spssdata(var) as allData:
misCnt = 0
for case in allData:
if case[0] is None:
misCnt += 1
if misCnt >= 15:
spssSyntax += var + ' '
#print spssSyntax + "."
spss.Submit(spssSyntax + ".")
end program.最后的说明
就这样。请注意,我们也可以修改此语法以从我们的数据中删除常量(每个个案都具有相同值的变量)。甚至可以删除方差较低的变量。这里基本限制是任何 WEIGHT (权重), FILTER (筛选) 或 SPLIT FILE (拆分文件) 都将被忽略,但这很少是一个问题。