在 SPSS 中创建符合 APA 格式的频数表
作者:Ruben Geert van den Berg,归属于 SPSS 表格 专题
统计学中最基础的表格可能就是简单的频数分布表了。然而,SPSS 默认生成的频数表却十分冗杂,并且不符合 APA(美国心理学会)的建议标准。
那么,如何创建更好、更快速的频数表呢?本教程将展示一个很棒的技巧!我们将使用 bank_clean.sav 数据集,其部分数据如下所示。
为什么 SPSS 默认频数表很糟糕
让我们仔细看看一些基本的频数表。可以通过运行以下 语法 来创建它们。
***仅在输出表格中显示值标签和变量标签。**
set
tnumbers labels
tvars labels.
***标准 SPSS 频数表。**
frequencies educ marit.结果
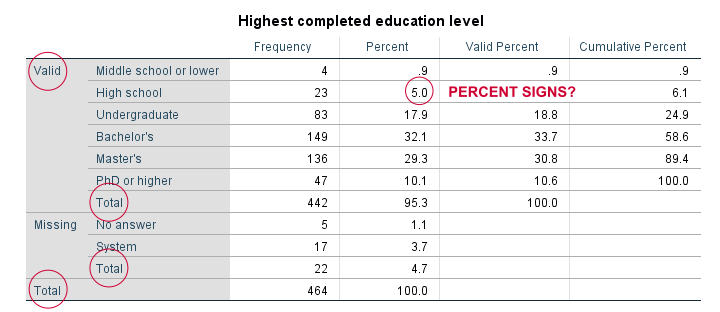
仅仅用于检查数据,或许这还可以。但是,这些表格不适合用于报告:
- SPSS 用户当然知道有效值 (valid) 和缺失值 (missing values) 之间的区别。但是,不使用 SPSS 的客户通常会觉得这令人困惑。
- “总计 (Total)” 在我们的表格中出现了不少于 3 次。
- 百分号 (%) 在百分比中缺失。
- 我们很少需要累计频数 (cumulative frequencies),而实际上是累计_有效_频数。
- SPSS 23 中引入的输出表格的新样式 (styling) 看起来很糟糕。
现在,样式问题很容易通过 表格外观 (tablelook) 来解决。应用它之后,我们的表格看起来好多了,如下所示。

不幸的是,FREQUENCIES 命令没有选项可以避免我们刚才提到的其他问题。因此,让我们尝试一些完全不同的方法。
在 MEANS 表格中显示频数
好的,这听起来可能很疯狂,但请 - 真的 - 尝试一下。首先,我们将创建一个新变量,该变量为所有个案 (cases) 保存零值。接下来,我们将为我们的常量 (constant) 运行一个最小的 MEANS 表格,并以目标变量进行分组。让我们运行以下语法,看看会发生什么。
***向数据添加新变量,所有个案的值相同。**
compute constant = 0.
***基本的 MEANS 表格,常量按 educ 和 marit 分组。**
means constant by educ marit.结果
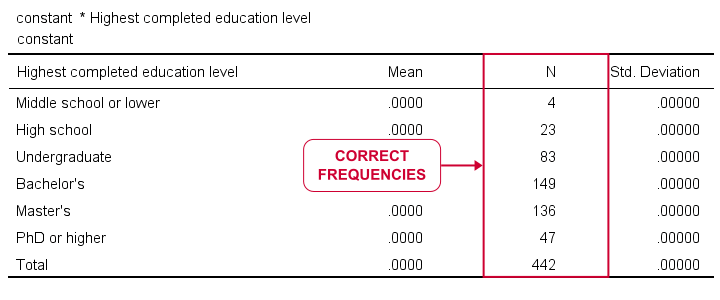
我们的表格看起来很愚蠢。显然,所有均值 (means) 和标准差 (standard deviations) 都是 0.000。但是,我们_确实_有干净简洁的频数,但我们没有相应的百分比。还没。
没有均值的 MEANS
现在的技巧是,MEANS 允许我们选择我们想要的列以及它们的顺序。因此,我们可以有_没有_均值或标准差的 MEANS,但_有_频数和百分比。这会生成符合 APA 推荐格式的漂亮而干净的频数表。
***设置常量的变量标签。**
variable labels constant ' **表格 ## ...** '。
***运行 MEANS 表格,但仅显示频数和百分比。**
means constant by educ marit
/cells count npct.
***可选:美化表格。**
output modify
/select tables
/table tabletitle = ' '
/tablecells select = ['% of Total N'] applyto = columnheader replace = '%'
/tablecells select = ['Total'] applyto = row style = bold.结果

首先请注意,我们将所需表格标题的一部分设置为常量的变量标签。如果您不想要这样做,请尝试运行 variable labels constant ' '。这样做之后,标题将由单个空格组成,因此看起来根本没有标题。
另请注意,我们使用 OUTPUT MODIFY 美化了我们的表格,这需要 SPSS 22 或更高版本。为了简单起见,我们处理了输出窗口中的_所有_表格。如果您不想这样做,向 OUTPUT MODIFY 添加一行或两行会将修改限制为对表格的精确选择。
如果您使用的是 SPSS 21 或更低版本,Ctrl + H 快捷键 - 无论是在 输出窗口 中还是在导出到 WORD 之后 - 都可以帮助删除或替换文本。
包括用户缺失值
默认情况下,我们的方法仅包括有效值。但是,只需向语法添加一行,就可以轻松包含 用户缺失值。
***相同的 APA 频数表,但包括用户缺失值。**
means constant by educ marit
/cells count npct
/missing include.包括系统缺失值
很少有 SPSS 过程可以包括 系统缺失值。但是,这很容易解决:我们将使用简单的 RECODE 将它们更改为某个巨大的数字。然后,我们给它一个值标签 (value label) 并将其设置为缺失值。
快速提示:不要使用非常_小_的数字,例如 -9999。小数字通常最终会成为表格中的第一行,而不是最后一行。
***将系统缺失值重新编码为巨大的值。**
recode educ marit (sysmis = 999999999).
***添加值标签。**
add value labels educ marit 999999999 '(问题跳过)'。
***将 999999999 设置为用户缺失值。**
missing values educ marit (999999999,7).
***运行带有用户缺失值和系统缺失值的 APA 频数。**
means constant by educ marit
/cells count npct
/missing include.结果

从 CTABLES 生成 APA 频数表
对我来说,像我们刚才讨论的那样创建频数表是首选选项。它快速而简单。但是,另一种方法是使用 CTABLES,但这需要自定义表格选项的许可证 (license)。
CTABLES 可以一次为一个或多个变量创建单个频数表。以下语法提供了一个最小的示例。
***多个变量的 APA 频数表。**
ctables
/table (educ + jtype) [count 'n' colpct.count '%'].结果

以上就是关于频数表的内容。希望本教程对您有所帮助!