SPSS 单样本卡方检验
作者:Ruben Geert van den Berg,发布于 卡方检验

SPSS 的单样本卡方检验 (One-Sample Chi-Square Test) 用于检验单个分类变量是否符合假设的总体分布。
SPSS 单样本卡方检验示例
一位营销人员认为 4 个智能手机品牌具有相同的吸引力。他询问了 43 个人他们更喜欢哪个品牌,结果保存在 brands.sav 文件中。如果这些品牌真的具有相同的吸引力,那么每个品牌应该被大致相同数量的受访者选择。换句话说,在零假设 (Null Hypothesis) 下,期望频数 (Expected Frequencies) 对于每个品牌都是 (43 个案例 / 4 个品牌 =) 10.75 个案例。观察频数 (Observed Frequencies) 与这些期望频数差异越大,品牌真正具有相同吸引力的可能性就越小。
1. 快速数据检查
在运行任何统计检验之前,我们总是希望了解数据的基本情况。在这种情况下,我们将通过运行 FREQUENCIES 命令来检查首选品牌的直方图。我们将打开数据文件并通过运行以下 语法 (Syntax) 来创建我们的直方图。因为非常简单,所以我们就不再通过菜单点击操作了。
***1. 设置默认目录。**
cd 'd:/downloaded'. /*或者数据文件所在的任何位置。*/
***2. 打开数据文件。**
get file 'brands.sav'.
***3. 检查数据。**
frequencies brand/histogram.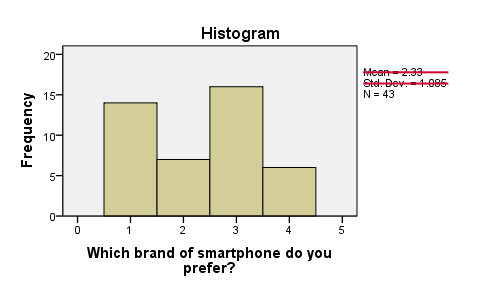
首先,N = 43 表示直方图基于 43 个案例。由于这是我们的样本大小,我们得出结论,不存在 缺失值 (Missing Values)。SPSS 还计算了平均值和标准差,但这些对于名义变量 (Nominal Variables) 没有意义,因此我们只需忽略它们。其次,首选品牌的频数非常不相等,这给那些品牌在总体中相等的零假设带来了一些疑问。
单样本卡方检验的假设
- 变量独立且同分布(或“独立观察”);
- 没有一个期望频数 < 5;
第一个假设超出了本教程的范围。我们假设我们的数据已经满足了它。无论假设 2 是否成立,SPSS 都会在我们运行单样本卡方检验时报告。但是,我们已经看到我们所有数据的期望频数都是 10.75。
3. 运行 SPSS 单样本卡方检验
 期望值 (Expected Values) 指的是期望频数,即每个品牌上述的 10.75 个案例。我们可以输入这些值,但选择 “所有类别相等 (All categories equal)” 是一个更快的选项,并且会产生相同的结果。
期望值 (Expected Values) 指的是期望频数,即每个品牌上述的 10.75 个案例。我们可以输入这些值,但选择 “所有类别相等 (All categories equal)” 是一个更快的选项,并且会产生相同的结果。  点击 “粘贴 (Paste)” 会产生以下语法。
点击 “粘贴 (Paste)” 会产生以下语法。
***1. 设置默认目录。**
cd 'd:/downloaded'. /*或者数据文件所在的任何位置。*/
***2. 打开数据文件。**
get file 'brands.sav'.
***3. 卡方检验(从 分析 (Analyze) - 非参数检验 (Nonparametric Tests) - 旧对话框 (Legacy Dialogs) - 卡方 (Chi-square) 粘贴)。**
NPAR TESTS
/CHISQUARE=brand
/EXPECTED=EQUAL
/MISSING ANALYSIS.4. SPSS 单样本卡方检验输出
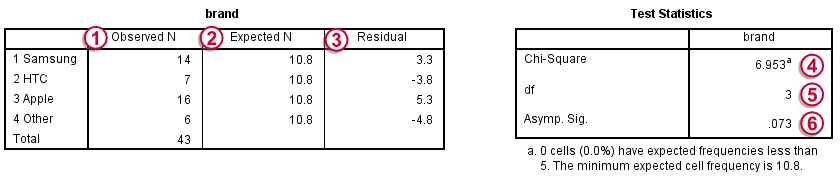
 在 观察 N (Observed N) 下,我们可以找到之前看到的观察频数;
在 观察 N (Observed N) 下,我们可以找到之前看到的观察频数;  在 期望 N (Expected N) 下,我们可以找到理论上期望的频数;由于四舍五入,它们显示为 10.8 而不是 10.75。可以通过双击该值来查看所有报告的小数位。 对于每个频数,残差 (Residual) 是观察频数和期望频数之间的差异,因此表示与零假设的偏差; 卡方 (Chi-Square) 检验统计量对残差进行某种总结,因此指示数据与假设之间的总体差异。卡方值越大,数据与零假设的“拟合”程度越低;
在 期望 N (Expected N) 下,我们可以找到理论上期望的频数;由于四舍五入,它们显示为 10.8 而不是 10.75。可以通过双击该值来查看所有报告的小数位。 对于每个频数,残差 (Residual) 是观察频数和期望频数之间的差异,因此表示与零假设的偏差; 卡方 (Chi-Square) 检验统计量对残差进行某种总结,因此指示数据与假设之间的总体差异。卡方值越大,数据与零假设的“拟合”程度越低;  自由度 (degrees of freedom)(df)指定适用的卡方分布;
自由度 (degrees of freedom)(df)指定适用的卡方分布;  渐近显著性 (Asymp. Sig.) 指的是 p 值 (p-value),在本例中为 .073。如果这些品牌在总体中完全具有相同的吸引力,那么有 7.3% 的机会找到我们观察到的频数或与零假设的更大偏差。如果 p < .05,我们通常会拒绝零假设。由于事实并非如此,我们得出结论,这些品牌在总体中具有相同的吸引力。
渐近显著性 (Asymp. Sig.) 指的是 p 值 (p-value),在本例中为 .073。如果这些品牌在总体中完全具有相同的吸引力,那么有 7.3% 的机会找到我们观察到的频数或与零假设的更大偏差。如果 p < .05,我们通常会拒绝零假设。由于事实并非如此,我们得出结论,这些品牌在总体中具有相同的吸引力。
报告单样本卡方检验
在报告单样本卡方检验时,我们总是报告观察频数。期望频数通常很容易从零假设中得出,因此报告它们是可选的。关于显著性检验,我们通常会写类似 “我们无法证明这四个品牌不具有相同的吸引力;χ2(3) = 6.95, p = .073.”