SPSS VARSTOCASES:用途与详解
作者:Ruben Geert van den Berg,归属于 SPSS A-Z 系列
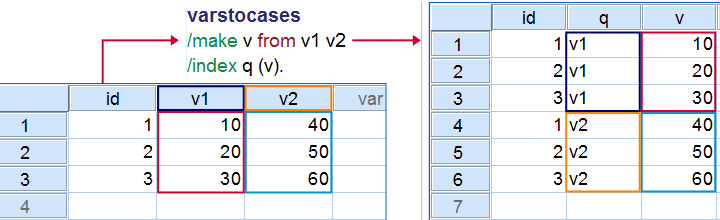
SPSS 中的 VARSTOCASES 命令是 “variables to cases”(变量转换为个案)的缩写。它的作用是重组数据,通过将多个变量堆叠在一起,转换成新的个案,如上图所示。你可以下载并打开 sav_data018 数据文件,并运行以下语法,亲自尝试这个简单的示例。
SPSS VARSTOCASES 示例 1
***非常基础的 VARSTOCASES 示例。**
varstocases
/make v from v1 v2
/index q (v).SPSS VARSTOCASES - 为什么使用它?
使用 VARSTOCASES 的一个重要原因是,许多 SPSS 图形只有在将相关变量堆叠在一起后才能生成。 此外,VARSTOCASES 还可以方便地生成一些表格。 例如,让我们看看 freelancers.sav 中的一些数据。
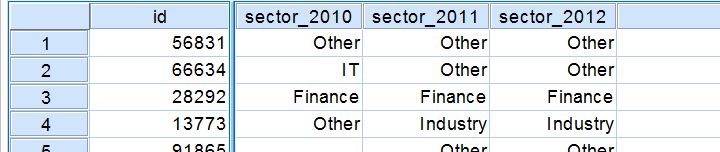
我们可能想比较受访者多年来从事的行业,如下表所示。
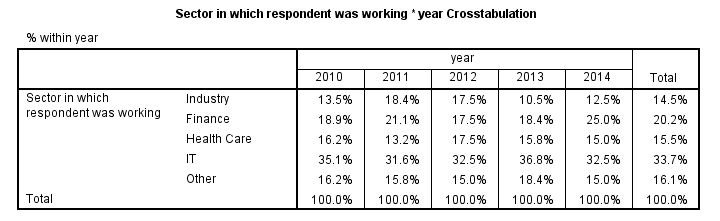
有道理,对吧? 现在,创建此表的一种方法是使用 CTABLES (custom tables,定制表),但这需要一个(付费)附加模块。 其次,TABLES 命令也可以实现此目的,但它仅在(具有挑战性的)语法中可用,并且不再有文档记录。
第三种选择是 VARSTOCASES,然后是 CROSSTABS 命令,如下所示。 请注意,VARSTOCASES 会导致不正确的 variable label(变量标签),因此我们在步骤 2 中对其进行更正。 我们稍后将讨论这个问题。
SPSS VARSTOCASES 示例 2
***1. Varstocases. **
varstocases
/make sector from sector_2010 to sector_2014
/index year(sector).
***2. Correct variable label. **
variable labels sector "Sector in which respondent was working".
***3. Extract year from string. **
compute year = char.substr(year,index(year,'_') + 1).
execute.
***4. Generate table. **
crosstabs sector by year/cells column.SPSS VARSTOCASES - 创建多个变量
我们前两个示例创建了一个包含原始值的一个变量,以及一个包含原始变量名称的第二个(索引)变量。 但是,在某些情况下,你可能希望一次性重组多组变量。 例如,让我们考虑 sav_data016 ,其中包含典型的反应时间数据。
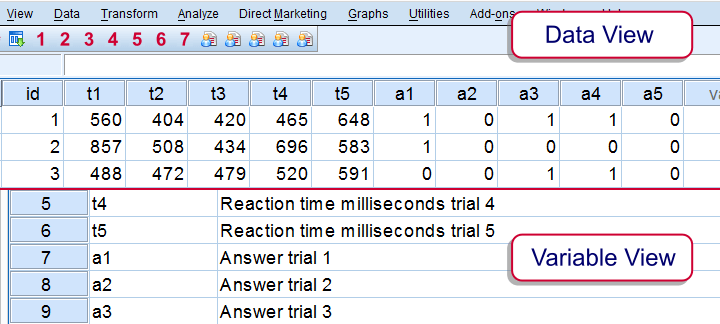
显然,受访者进行了 5 次试验,每次试验都产生一个答案和一个反应时间。 那么,错误的答案是否具有更短或更长的平均反应时间? 一种方法是使用以下 VARSTOCASES 语法,然后可能使用 MEANS 命令。
SPSS VARSTOCASES 示例 3
***Varstocases: two sets of variables. **
varstocases
/make t from t1 to t5
/make a from a1 to a5
/index trial.结果

SPSS VARSTOCASES - 错误结果
在我们的第二个示例中,我们将两个变量堆叠在一个新变量中。 两个输入变量都有一个变量标签 (variable label),但是(单个)输出变量只能有一个变量标签。 SPSS 通过使用它遇到的第一个变量标签来“解决”这个问题。 在大多数情况下,这将是不正确的,但我们会很容易看到这个问题。 VARSTOCASES 的真正问题在于,相同的原理也适用于值标签 (value label)。 这可能会导致无意义的结果。 我们现在将在 sav_data017 上演示这一点,该文件的一部分如下所示。

我们首先运行基本的 FREQUENCIES 命令。 请注意,这两个问题基本上表明,政治家在我们的受访者中不是很受欢迎。
***1. Show values and value labels in output. **
set tnumbers both.
***2. Frequency tables. **
frequencies v1 v2.结果

重要的是,这些表格还显示我们的两个变量具有不一致的值标签 (value label)。 我们现在运行 VARSTOCASES 命令,并使用单个列联表复制这两个频率表。
SPSS VARSTOCASES 示例 4
***1. Varstocases. **
varstocases
/make v from v1 v2
/index question(v).
***2. Remove incorrect variable label. **
variable labels v ''.
***3. Note that result is not correct. **
crosstabs v by question/cells columns.结果

请注意,VARSTOCASES 已将 v1 的值标签 (value label) 应用于 v1 和 v2 的值,从而导致误导性的结果。 更令人不安的是,SPSS 没有抛出任何错误或警告,表明在某个时候事情出了问题。
信不信由你,这不是一个错误。 VARSTOCASES 应该像这样工作,并且这种行为在 CSR 中进行了描述。 但是,我们想知道有多少 SPSS 用户意识到可能会发生这种情况。 即使是那些_意识到_这一点的人,也没有有效的方法来规避它,因为 SPSS 完全缺乏任何字典一致性检查。
就我个人而言,我们认为 VARSTOCASES 应该默认执行这样的检查,并且如果出现问题,至少发出警告。 此建议也适用于 ADD FILES 命令,该命令显示类似的问题行为,甚至更难避免。