我们通常在线性回归或者多元方差分析中听过这个词, 它通常指的是当回归模型中的自变量相关太高时,它们将无法独立预测因变量的值。换句话说,他们解释了因变量中的某些相同方差,从而降低了其统计显着性。
本篇文章主要介绍了诊断多重共线性的理论解释和解决方法。
假如我们调查了51人的工作年限(X1)/工作经验(X2)/工资水平(Y)这三个变量, 我们期望得到的回归方程是:
$$ Y = h + \beta_1 X_1 + \beta_2 X_2 + e (1式) $$

也就是说:
$$ h=-1.147 \\ \beta_1=.870 \\ \beta_2=.153 $$
但是实际上, $X_1$和$X_2$
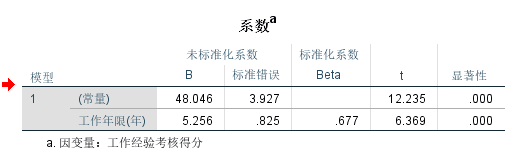
用spss统计的结果是这样的:
也就是说:
$$ h_3=48.046 \\ \beta_3=5.256 $$
假如我们将(2)式代入(1)式, 会得到下面的方程:
$$ Y = h + h_3 \beta_2 + \beta_1 X_1 + \beta_2 \beta_3 X_1 + e $$
从上面的式子中, 我们应当可以看出, 由于共线性的存在($\beta_3$不为0), 又由于$X_2$对Y有影响($\beta_2$不为0), 所以, 当我们考察$X_1$对Y的影响的时候, 只看$\beta_1$就会得出错误的结论, 而需要考察$\beta_1+\beta_2 \beta_3$
解决方法
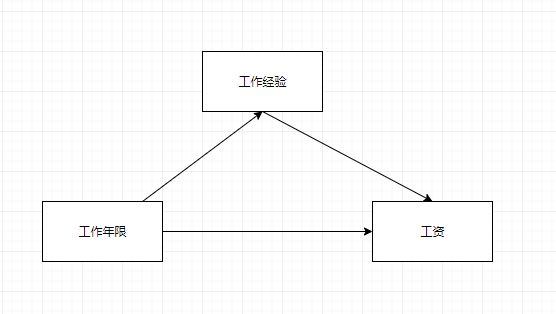
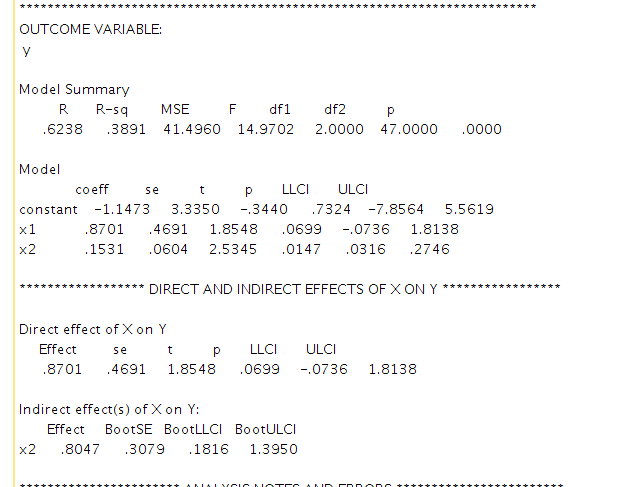
使用将”工作经验”设置为中介变量, 进行中介分析, 推荐使用spss的process插件。
注意
本文由jupyter notebook转换而来, 您可以在这里下载notebook
统计咨询请加QQ 2726725926, 微信 mllncn, SPSS统计咨询是收费的
微博上@mlln-cn可以向我免费题问
请记住我的网址: mlln.cn 或者 jupyter.cn


