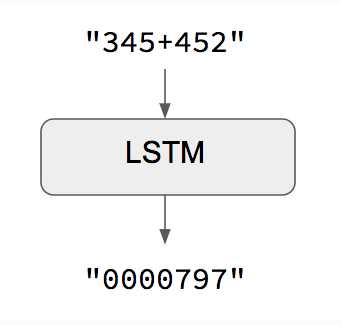
# Define the model that will turn # `encoder_input_data` & `decoder_input_data` into `decoder_target_data` model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
defdecode_sequence(input_seq): # Encode the input as state vectors. states_value = encoder_model.predict(input_seq)
# Generate empty target sequence of length 1. target_seq = np.zeros((1, 1, num_decoder_tokens)) # Populate the first character of target sequence with the start character. target_seq[0, 0, target_token_index['\t']] = 1.
# Sampling loop for a batch of sequences # (to simplify, here we assume a batch of size 1). stop_condition = False decoded_sentence = '' whilenot stop_condition: output_tokens, h, c = decoder_model.predict( [target_seq] + states_value)
# Exit condition: either hit max length # or find stop character. if (sampled_char == '\n'or len(decoded_sentence) > max_decoder_seq_length): stop_condition = True
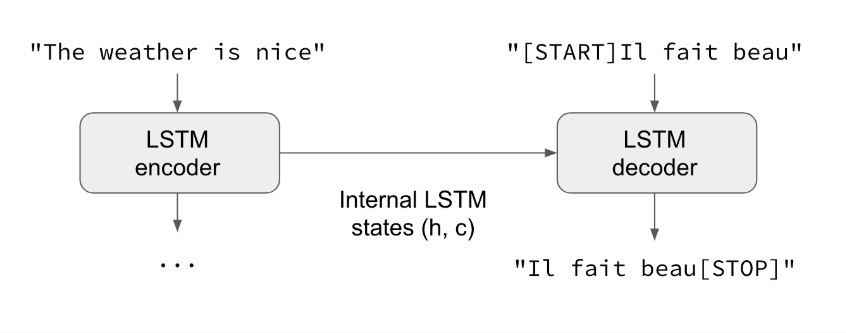
# Define an input sequence and process it. encoder_inputs = Input(shape=(None,)) x = Embedding(num_encoder_tokens, latent_dim)(encoder_inputs) x, state_h, state_c = LSTM(latent_dim, return_state=True)(x) encoder_states = [state_h, state_c]
# Set up the decoder, using `encoder_states` as initial state. decoder_inputs = Input(shape=(None,)) x = Embedding(num_decoder_tokens, latent_dim)(decoder_inputs) x = LSTM(latent_dim, return_sequences=True)(x, initial_state=encoder_states) decoder_outputs = Dense(num_decoder_tokens, activation='softmax')(x)
# Define the model that will turn # `encoder_input_data` & `decoder_input_data` into `decoder_target_data` model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Compile & run training model.compile(optimizer='rmsprop', loss='categorical_crossentropy') # Note that `decoder_target_data` needs to be one-hot encoded, # rather than sequences of integers like `decoder_input_data`! model.fit([encoder_input_data, decoder_input_data], decoder_target_data, batch_size=batch_size, epochs=epochs, validation_split=0.2)
from keras.layers import Lambda from keras import backend as K
# The first part is unchanged encoder_inputs = Input(shape=(None, num_encoder_tokens)) encoder = LSTM(latent_dim, return_state=True) encoder_outputs, state_h, state_c = encoder(encoder_inputs) states = [state_h, state_c]
# Set up the decoder, which will only process one timestep at a time. decoder_inputs = Input(shape=(1, num_decoder_tokens)) decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True) decoder_dense = Dense(num_decoder_tokens, activation='softmax')
all_outputs = [] inputs = decoder_inputs for _ inrange(max_decoder_seq_length): # Run the decoder on one timestep outputs, state_h, state_c = decoder_lstm(inputs, initial_state=states) outputs = decoder_dense(outputs) # Store the current prediction (we will concatenate all predictions later) all_outputs.append(outputs) # Reinject the outputs as inputs for the next loop iteration # as well as update the states inputs = outputs states = [state_h, state_c]
# Concatenate all predictions decoder_outputs = Lambda(lambda x: K.concatenate(x, axis=1))(all_outputs)
# Define and compile model as previously model = Model([encoder_inputs, decoder_inputs], decoder_outputs) model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# Prepare decoder input data that just contains the start character # Note that we could have made it a constant hard-coded in the model decoder_input_data = np.zeros((num_samples, 1, num_decoder_tokens)) decoder_input_data[:, 0, target_token_index['\t']] = 1.
# Train model as previously model.fit([encoder_input_data, decoder_input_data], decoder_target_data, batch_size=batch_size, epochs=epochs, validation_split=0.2)