简介
Kohonen自组织特征映射或SOMs,是由芬兰科学院教授Teuvo Kohonen发明的,他们提供了一种在低维空间(通常是一维或二维)表示多维数据的方法。这个降低矢量维度的过程本质上是一种称为矢量量化的数据压缩技术。此外,Kohonen技术创建了一个网络,以这种方式存储信息,以保持训练集内的任何拓扑关系。
SOM一个常见示例是将颜色从其三维空间(红色,绿色和蓝色)映射到两个维度。图1显示了一个SOM训练的例子,用于识别右侧显示的八种不同颜色。颜色作为向量呈现给网络 - 每个颜色分量都有一个维度 - 网络已经学会在二维空间中表示它们。注意,除了将颜色聚类到不同的区域之外,通常还会发现类似属性的区域彼此相邻。
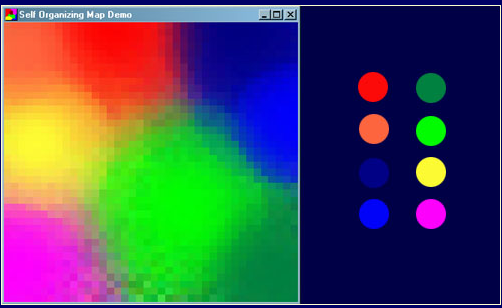 图1 经过训练的SOM
图1 经过训练的SOM
网络结构
SOM(Self Organizing Feature Maps)的网络结构非常简单, 很适合作为一个入门案例. 如图2所示, 本教程讨论的是一个二维SOM. 这个网络可以被当作一个两层网络: 输入层和输出层. 输入层只有一个节点, 我们用X表示输入, 输出层是一个7x7的矩阵或者说表格. 因为我们要对颜色进行分类, 所以我们设输入向量x是一个三维向量, 如[0 0 1], 代表一种颜色. 输出层的每个神经元有一个权重向量W, 我们这个网络中就有49个权重向量, 而且向量的维数与输入向量相等, 也是3, 这样这些权重向量也可以被当作一种颜色的数值表示, 所以可以被可视化成图1的样子.
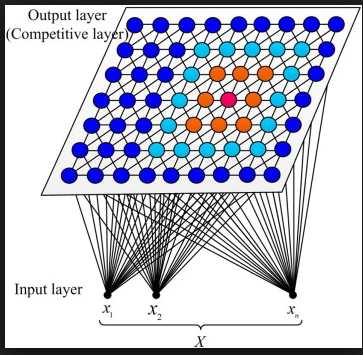 图2 SOM神经网络架构
图2 SOM神经网络架构
学习过程
SOM是无监督学习, 不需要成对的数据. SOM的学习过程可以总结成一句话, 就是调整输出层权重W以便于让相邻的节点具有相似的权重. 具体来说分为一下的步骤:
- 每个节点的权重都被随机初始化。
- 从训练数据集中随机选择向量x并将其输入到网格。
- 检查每个输出层节点以计算哪一个的权重最像输入向量。获胜节点通常被称为最佳匹配单元(BMU)或激活单元。
- 现在计算BMU邻域节点, 以BMU为圆心, 处于半径R内的节点都被称为邻域。R是一个开始较大的值,通常设置为输出层的“半径”,但会随着训练逐步减小。在该半径内发现的任何节点都被视为在BMU的邻域内。
- 调整每个邻域节点(步骤4中找到的节点)权重以使它们更像输入向量。节点越靠近BMU,其权重调整的就越大。
- N次迭代重复步骤2。
代码实现
下面我们用tensorflow逐步实现这些过程.
初始化权重
1 | import tensorflow as tf |
1 | def _locations(shape): |
1 | vs = init() |
寻找最佳匹配单元BMU
用欧几里得距离来衡量两个向量之间的相似性. 公式是:

1 | def calculate_bmu(weights, x): |
通过下面代码大概测试一下程序是否能跑通
1 | vs = init() |
计算邻域节点
首先我们要确定邻域的半径, 然后才能找到半径以内的节点.
计算邻域半径的公式是:

其中, t表示时间步骤, 可以把它当作训练的迭代次数, $\sigma$ 表示半径, $\sigma_0$表示输出层矩阵的宽度, $\lambda$
1 | def calculate_radius_lrate(iter_step, num_iters, radius0, learning_rate0): |
简单测试上面的函数, 确保能正常运行:
1 | vs = init() |
1 | bmu_index = tf.constant([85], dtype=tf.float64) |
更新权重
我们先来看一下, 权重的更新公式:
$$ W(t+1) = W(t) + Θ(t)L(t)(X(t) - W(t)) $$
公式中符号的意义:
$X(t)$t时刻的输入$W(t)$t时刻的权重$W(t+1)$t+1时刻的权重$L(t)$t时刻的学习率, 所有邻域内的神经元具有相同的$L(t)$$Θ(t)$t时刻某个神经元距离bmu的距离的函数, 是学习率的权重, 它使得距离bmu近的神经元更新的权重更大, 受输入的影响更多
计算$L(t)$的公式如下:
$$ L(t) = L_0 \exp(- {t \over \lambda}) ; t = 1, 2, 3 ... $$
其中:
- t代表时间步, 也叫当前迭代次数
$\lambda$代表总迭代次数$L_0$代表初始的学习率, 通常是输出层矩阵的长度或宽度
计算$Θ(t)$的公式如下:
$$ \Theta(t) = \exp ( -{dist^2 \over {2\sigma^2(t)}} ) $$
1 | def theta(radius, dist_square): |
计算$L(t)$
$L(t)$
更新权重
1 | def update_weights(weights, mask, xt, lr, theta): |
测试以上函数
1 | radius, learning_rate = calculate_radius_lrate(iter_step, vs['num_iters'], vs['radius'], vs['learning_rate']) |
1 | x = vs['x'] |
训练
现在即将要大功告成, 我们需要整合上面所有的函数, 然后进行训练.
训练数据
训练数据就是15种颜色. 将这些数据迭代1000次.
1 | colors = np.array( |
输出层可视化函数
这个函数用于监控在训练过程种输出层权重的变化.
1 | from matplotlib import pyplot as plt |
训练函数
1 |
|
1 | %matplotlib inline |


注意
本文由jupyter notebook转换而来, 您可以在这里下载notebook
统计咨询请加QQ 2726725926, 微信 mllncn, SPSS统计咨询是收费的
微博上@mlln-cn可以向我免费题问
请记住我的网址: mlln.cn 或者 jupyter.cn


