import numpy as np import h5py import matplotlib.pyplot as plt
%matplotlib inline plt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots plt.rcParams['image.interpolation'] = 'nearest' plt.rcParams['image.cmap'] = 'gray'
%load_ext autoreload %autoreload 2
np.random.seed(1)
d:\mysites\deeplearning.ai-master\.env\lib\site-packages\h5py\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
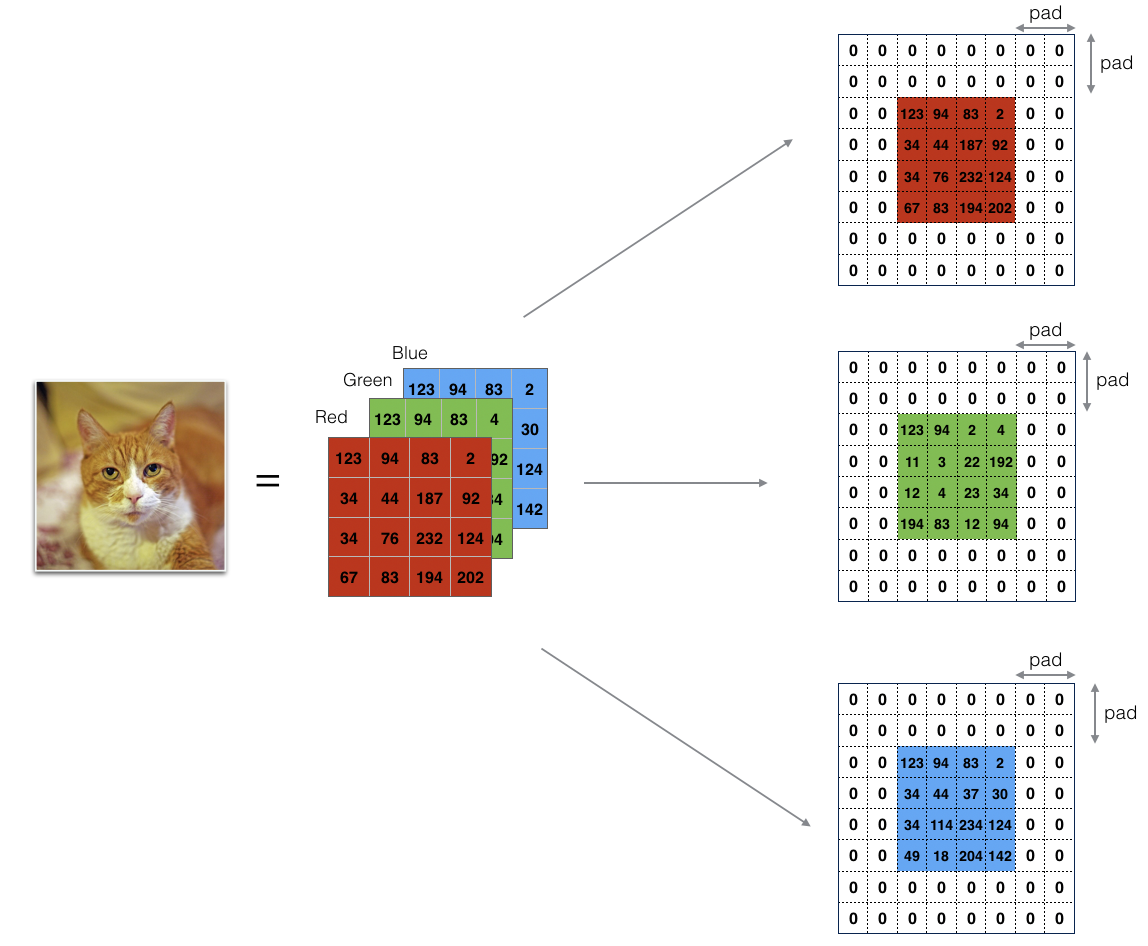
defzero_pad(X, pad): """ 用零填充数据集X的所有图像。填充应用于图像的高度和宽度, 如图1所示。 Argument: X -- python numpy array of shape (m, n_H, n_W, n_C) representing a batch of m images pad -- integer, amount of padding around each image on vertical and horizontal dimensions Returns: X_pad -- padded image of shape (m, n_H + 2*pad, n_W + 2*pad, n_C) """ X_pad = np.pad(X,((0,0),(pad,pad),(pad,pad),(0,0)),'constant',constant_values = 0) return X_pad
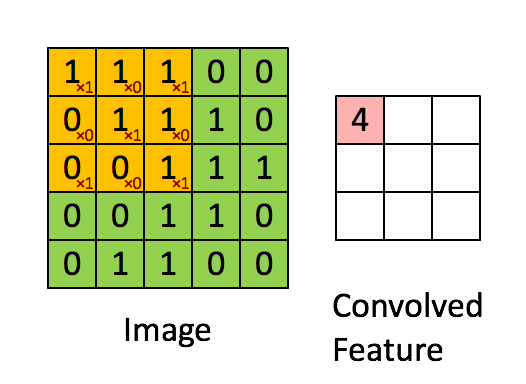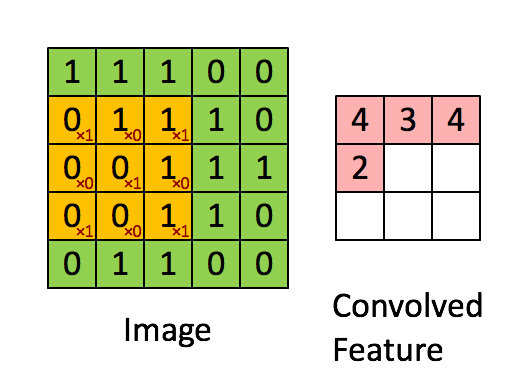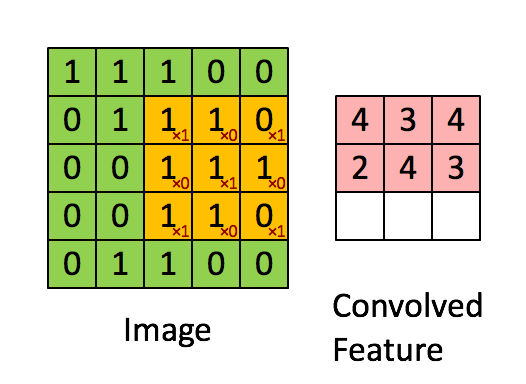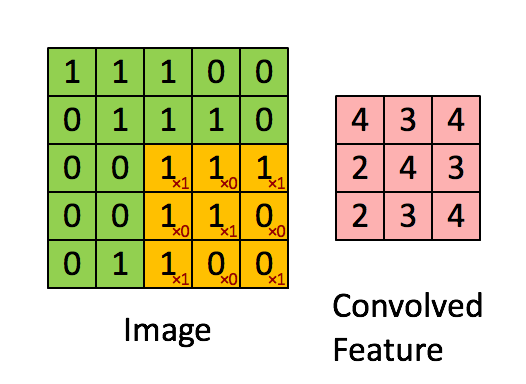
defconv_single_step(a_slice_prev, W, b): """ Apply one filter defined by parameters W on a single slice (a_slice_prev) of the output activation of the previous layer. Arguments: a_slice_prev -- slice of input data of shape (f, f, n_C_prev) W -- Weight parameters contained in a window - matrix of shape (f, f, n_C_prev) b -- Bias parameters contained in a window - matrix of shape (1, 1, 1) Returns: Z -- a scalar value, result of convolving the sliding window (W, b) on a slice x of the input data """
# Element-wise product between a_slice and W. Do not add the bias yet. s = np.multiply(a_slice_prev, W) # Sum over all entries of the volume s. Z = np.sum(s) # Add bias b to Z. Cast b to a float() so that Z results in a scalar value. Z = float(b)+Z
return Z
1 2 3 4 5 6 7
np.random.seed(1) a_slice_prev = np.random.randn(4, 4, 3) W = np.random.randn(4, 4, 3) b = np.random.randn(1, 1, 1)
Z = conv_single_step(a_slice_prev, W, b) print("Z =", Z)
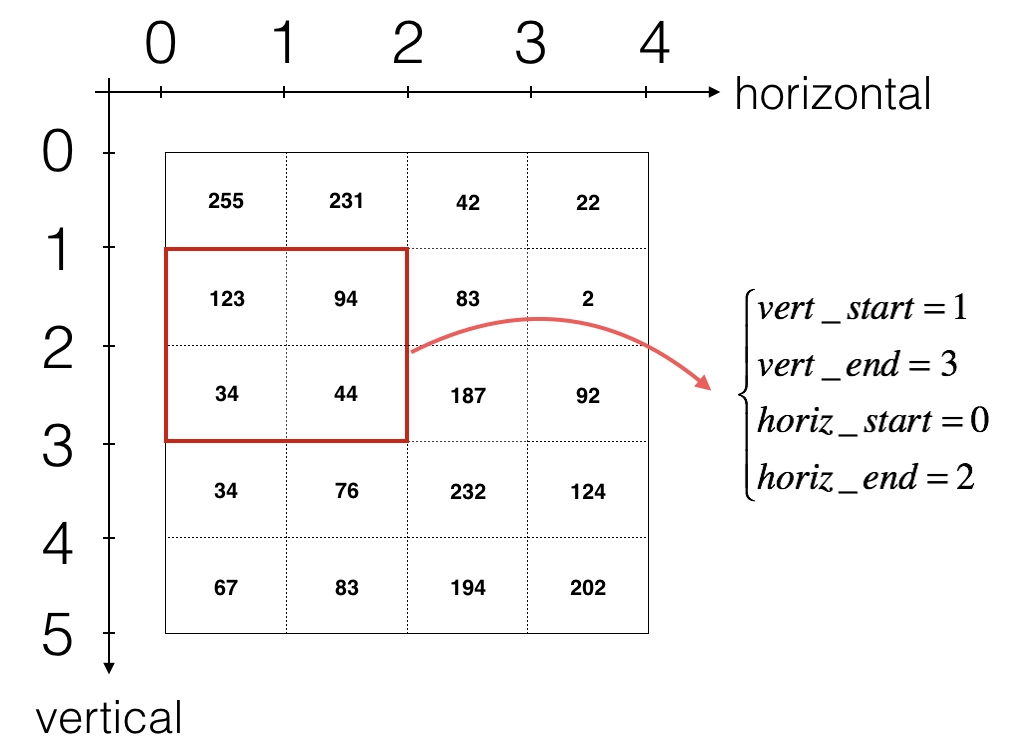
defconv_forward(A_prev, W, b, hparameters): """ 实现卷积函数的前向传播 Arguments: A_prev -- output activations of the previous layer, numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev) W -- Weights, numpy array of shape (f, f, n_C_prev, n_C) b -- Biases, numpy array of shape (1, 1, 1, n_C) hparameters -- python dictionary containing "stride" and "pad" Returns: Z -- conv output, numpy array of shape (m, n_H, n_W, n_C) cache -- cache of values needed for the conv_backward() function """ # Retrieve dimensions from A_prev's shape (≈1 line) # 如果你不理解下面的符号可以看上面的公式 (m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape ''' m: 数据样本量 n_H_prev: 图像宽度 n_W_prev: 图像高度 n_C_prev: 通道数 ''' # Retrieve dimensions from W's shape (≈1 line) # 如果你不理解下面的符号可以看上面的公式 (f, f, n_C_prev, n_C) = W.shape # Retrieve information from "hparameters" (≈2 lines) stride = hparameters['stride'] pad = hparameters['pad'] # 使用上面的公式计算卷积层输出维度. Hint: use int() to floor. (≈2 lines) n_H = int((n_H_prev-f+2*pad)/stride+1) n_W = int((n_W_prev-f+2*pad)/stride+1) # Initialize the output volume Z with zeros. (≈1 line) # 注意这些参数都很重要: # m: 样本量 # n_H: 输出的高 # n_W: 输出的宽 # n_C: 输出的通道数(深度) Z = np.zeros([m,n_H,n_W,n_C]) # Create A_prev_pad by padding A_prev A_prev_pad = zero_pad(A_prev, pad) for i inrange(m): # loop over the batch of training examples a_prev_pad = A_prev_pad[i,:,:,:] # Select ith training example's padded activation for h inrange(n_H-f+1): # 遍历垂直方向 for w inrange(n_W-f+1): # l遍历水平方向 for c inrange(n_C): # 遍历filter个数 # Find the corners of the current "slice" (≈4 lines) vert_start = h vert_end = h+f horiz_start = w horiz_end = w+f # Use the corners to define the (3D) slice of a_prev_pad (See Hint above the cell). (≈1 line) a_slice_prev = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:] # Convolve the (3D) slice with the correct filter W and bias b, to get back one output neuron. (≈1 line) Z[i, h, w, c] = conv_single_step(a_slice_prev, W[:,:,:,c], b[:,:,:,c]) # Making sure your output shape is correct assert(Z.shape == (m, n_H, n_W, n_C)) # Save information in "cache" for the backprop cache = (A_prev, W, b, hparameters) return Z, cache
1 2 3 4 5 6 7 8 9 10 11 12
np.random.seed(1) A_prev = np.random.randn(10,4,4,3) W = np.random.randn(2,2,3,8) b = np.random.randn(1,1,1,8) hparameters = {"pad" : 2, "stride": 2}
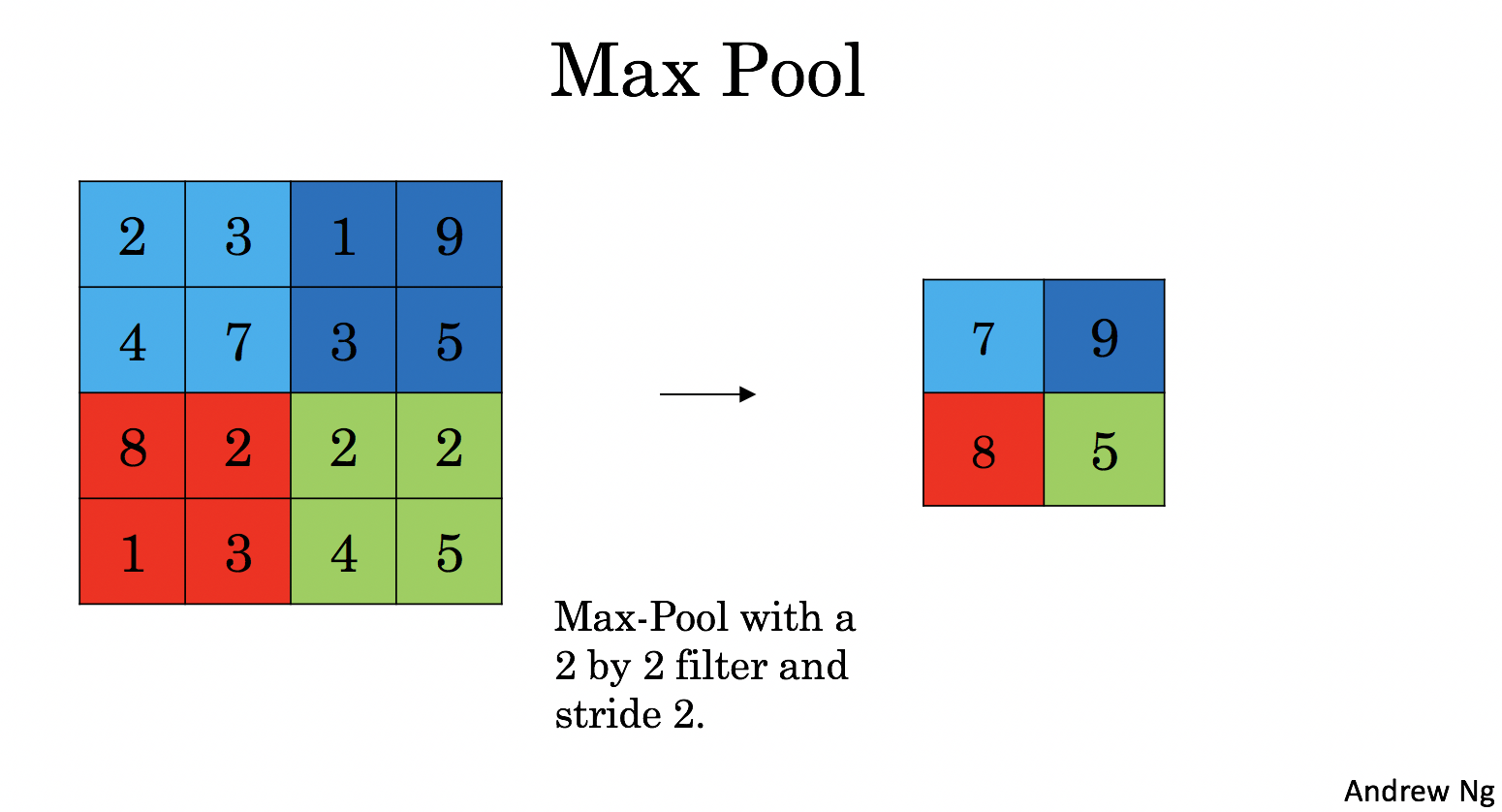
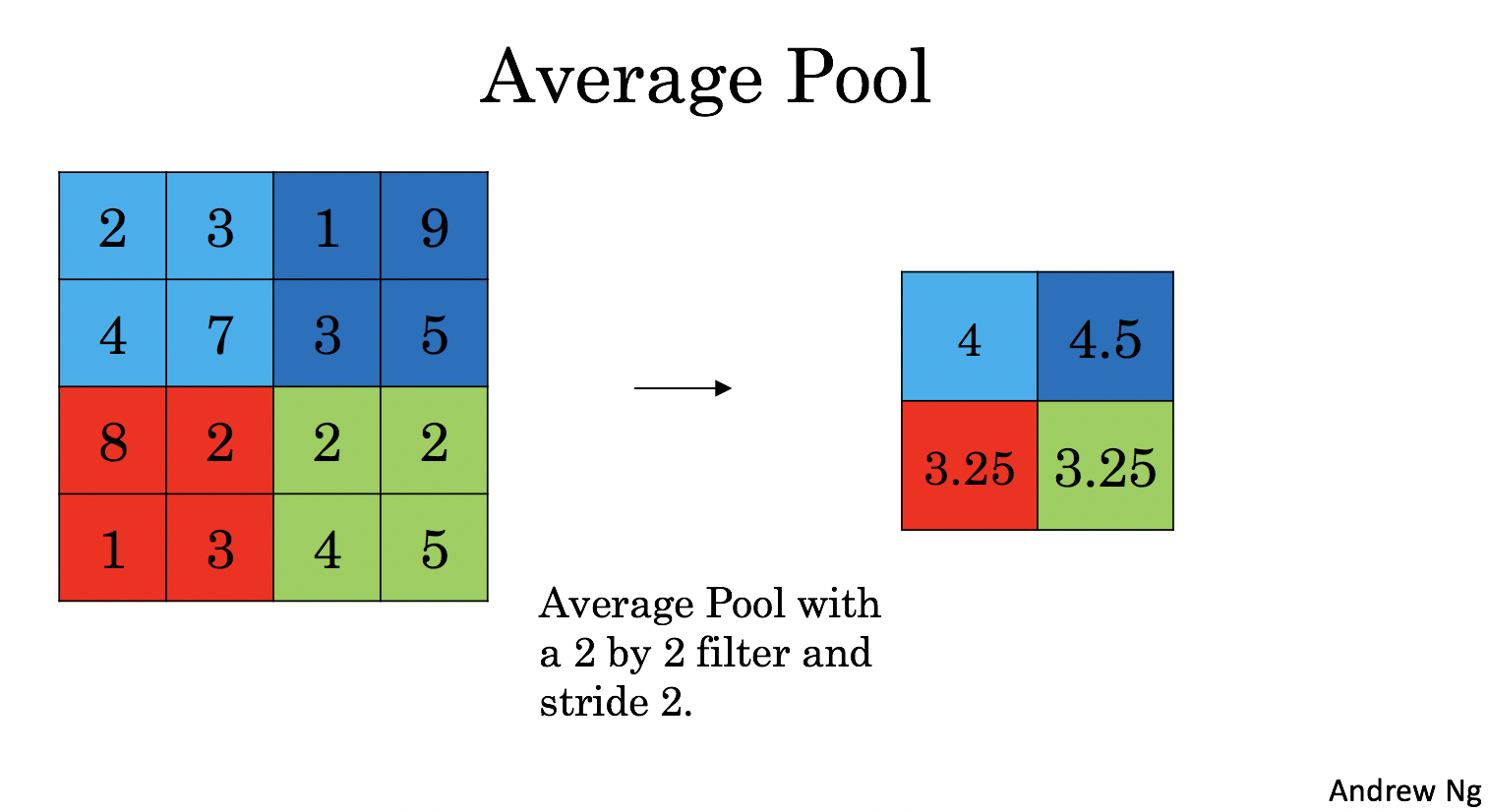
defpool_forward(A_prev, hparameters, mode = "max"): """ 实现池化层的前向传播 Arguments: A_prev -- Input data, numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev) hparameters -- python dictionary containing "f" and "stride" mode -- the pooling mode you would like to use, defined as a string ("max" or "average") Returns: A -- output of the pool layer, a numpy array of shape (m, n_H, n_W, n_C) cache -- cache used in the backward pass of the pooling layer, contains the input and hparameters """ # Retrieve dimensions from the input shape (m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape # Retrieve hyperparameters from "hparameters" f = hparameters["f"] stride = hparameters["stride"] # Define the dimensions of the output n_H = int(1 + (n_H_prev - f) / stride) n_W = int(1 + (n_W_prev - f) / stride) n_C = n_C_prev # Initialize output matrix A A = np.zeros((m, n_H, n_W, n_C)) for i inrange(m): # 循环m个样本 for h inrange(n_H): # 循环垂直方向 for w inrange(n_W): # 循环水平方向 for c inrange (n_C): # 循环通道 # 定位 "slice" (≈4 lines) vert_start = h*stride vert_end = vert_start+f horiz_start = w*stride horiz_end = horiz_start+f # 用定位来生成切片. (≈1 line) a_prev_slice = A_prev[vert_start:vert_end,horiz_start:horiz_end,c] # Compute the pooling operation on the slice. Use an if statment to differentiate the modes. Use np.max/np.mean. if mode == "max": A[i, h, w, c] = np.max(a_prev_slice) elif mode == "average": A[i, h, w, c] = np.mean(a_prev_slice) # Store the input and hparameters in "cache" for pool_backward() cache = (A_prev, hparameters) # Making sure your output shape is correct assert(A.shape == (m, n_H, n_W, n_C)) return A, cache
其中$ W_c $是一个过滤器,$ dZ_ {hw} $是一个标量,对应于第h行和第w列的conv层Z输出的成本梯度(对应于在第步走,j步走下)。请注意,在每次更新dA时,我们都会将相同的过滤器$ W_c $乘以不同的dZ。我们这样做主要是因为在计算正向传播时,每个过滤器都被不同的a_slice点分和相加。因此,在计算dA的backprop时,我们只是添加所有a_slices的渐变。 In code, inside the appropriate for-loops, this formula translates into:
defconv_backward(dZ, cache): """ 实现卷积函数的反向传播 Arguments: dZ -- 相对于loss函数的卷积层的输出(Z)的梯度,形状的numpy阵列(m,n_H,n_W,n_C) cache -- conv_backward()所需值的缓存,conv_forward()的输出 Returns: dA_prev -- 相对于conv层的输入的loss的梯度 (A_prev), numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev) dW -- gradient of the cost with respect to the weights of the conv layer (W) numpy array of shape (f, f, n_C_prev, n_C) db -- gradient of the cost with respect to the biases of the conv layer (b) numpy array of shape (1, 1, 1, n_C) """ # Retrieve information from "cache" (A_prev, W, b, hparameters) = cache # Retrieve dimensions from A_prev's shape (m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape # Retrieve dimensions from W's shape (f, f, n_C_prev, n_C) = W.shape # Retrieve information from "hparameters" stride = hparameters['stride'] pad = hparameters['pad'] # Retrieve dimensions from dZ's shape (m, n_H, n_W, n_C) = dZ.shape # Initialize dA_prev, dW, db with the correct shapes dA_prev = np.zeros(A_prev.shape) dW = np.zeros(W.shape) db = np.zeros(b.shape)
# Pad A_prev and dA_prev A_prev_pad = zero_pad(A_prev, pad) dA_prev_pad = zero_pad(dA_prev, pad) for i inrange(m): # loop over the training examples # select ith training example from A_prev_pad and dA_prev_pad a_prev_pad = A_prev_pad[i,:,:,:] da_prev_pad = dA_prev_pad[i,:,:,:] for h inrange(n_H-f+1): # loop over vertical axis of the output volume for w inrange(n_W-f+1): # loop over horizontal axis of the output volume for c inrange(n_C): # loop over the channels of the output volume # Find the corners of the current "slice" vert_start = h vert_end = h+f horiz_start = w horiz_end = w+f # Use the corners to define the slice from a_prev_pad a_slice = a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]
# Update gradients for the window and the filter's parameters using the code formulas given above da_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :] += W[:,:,:,c] * dZ[i, h, w, c] dW[:,:,:,c] += a_slice * dZ[i, h, w, c] db[:,:,:,c] += dZ[i, h, w, c] # Set the ith training example's dA_prev to the unpaded da_prev_pad (Hint: use X[pad:-pad, pad:-pad, :]) dA_prev[i, :, :, :] = da_prev_pad[pad:-pad, pad:-pad, :] ### END CODE HERE ### # Making sure your output shape is correct assert(dA_prev.shape == (m, n_H_prev, n_W_prev, n_C_prev)) return dA_prev, dW, db
1 2 3 4 5
np.random.seed(1) dA, dW, db = conv_backward(Z, cache_conv) print("dA_mean =", np.mean(dA)) print("dW_mean =", np.mean(dW)) print("db_mean =", np.mean(db))
defcreate_mask_from_window(x): """ Creates a mask from an input matrix x, to identify the max entry of x. Arguments: x -- Array of shape (f, f) Returns: mask -- Array of the same shape as window, contains a True at the position corresponding to the max entry of x. """ ### START CODE HERE ### (≈1 line) mask = (x==np.max(x)) ### END CODE HERE ### return mask
defdistribute_value(dz, shape): """ 将输入值分布在维形状的矩阵中 Arguments: dz -- input scalar shape -- the shape (n_H, n_W) of the output matrix for which we want to distribute the value of dz Returns: a -- Array of size (n_H, n_W) for which we distributed the value of dz """ ### START CODE HERE ### # Retrieve dimensions from shape (≈1 line) (n_H, n_W) = shape # Compute the value to distribute on the matrix (≈1 line) average = dz/(n_H*n_W) # Create a matrix where every entry is the "average" value (≈1 line) a = average*np.ones([n_H,n_W]) ### END CODE HERE ### return a
1 2
a = distribute_value(2, (2,2)) print('distributed value =', a)
defpool_backward(dA, cache, mode = "max"): """ 实现池化层的后向传递 Arguments: dA -- gradient of cost with respect to the output of the pooling layer, same shape as A cache -- cache output from the forward pass of the pooling layer, contains the layer's input and hparameters mode -- the pooling mode you would like to use, defined as a string ("max" or "average") Returns: dA_prev -- gradient of cost with respect to the input of the pooling layer, same shape as A_prev """ # Retrieve information from cache (≈1 line) (A_prev, hparameters) = cache # Retrieve hyperparameters from "hparameters" (≈2 lines) stride =hparameters['stride'] f = hparameters['f'] # Retrieve dimensions from A_prev's shape and dA's shape (≈2 lines) m, n_H_prev, n_W_prev, n_C_prev = A_prev.shape m, n_H, n_W, n_C = dA.shape # Initialize dA_prev with zeros (≈1 line) dA_prev = np.zeros(A_prev.shape) for i inrange(m): # loop over the training examples # select training example from A_prev (≈1 line) a_prev = A_prev[i,:,:,:] for h inrange(n_H_prev-f+1): # loop on the vertical axis for w inrange(n_W_prev-f+1): # loop on the horizontal axis for c inrange(n_C): # loop over the channels (depth) # Find the corners of the current "slice" (≈4 lines) vert_start = h vert_end = h+f horiz_start = w horiz_end = w+f # Compute the backward propagation in both modes. if mode == "max": # Use the corners and "c" to define the current slice from a_prev (≈1 line) a_prev_slice = a_prev[vert_start:vert_end,horiz_start:horiz_end,c] # Create the mask from a_prev_slice (≈1 line) mask = create_mask_from_window(a_prev_slice) # Set dA_prev to be dA_prev + (the mask multiplied by the correct entry of dA) (≈1 line) dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += np.multiply(mask,dA[i,vert_start: vert_end, horiz_start: horiz_end,c]) elif mode == "average": # Get the value a from dA (≈1 line) da = np.mean(dA[i, vert_start: vert_end, horiz_start: horiz_end,c]) # Define the shape of the filter as fxf (≈1 line) shape = (f,f) # Distribute it to get the correct slice of dA_prev. i.e. Add the distributed value of da. (≈1 line) dA_prev[i, vert_start: vert_end, horiz_start: horiz_end, c] += distribute_value(da, shape)+da # Making sure your output shape is correct assert(dA_prev.shape == A_prev.shape) return dA_prev
mode = max
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 0. 0. ]
[ 10.11330283 -0.49726956]
[ 0. 0. ]]
mode = average
mean of dA = 0.145713902729
dA_prev[1,1] = [[ 2.59843096 -0.27835778]
[ 7.96018612 -1.95394424]
[ 5.36175516 -1.67558646]]